多智能体主持演讲者选择
在复杂的多角色对话系统中,如何动态选择发言者、保持对话节奏与主题一致,是实现“智能对话编排”的关键。本节将展示如何基于 LazyLLM 框架,构建一个具备“导演式调度”能力的多智能体对话系统,使不同角色能够在特定话题下进行自然且层次分明的互动。
在该示例中,系统引入了一个 Director(导演代理) 来控制发言顺序与对话终止逻辑,其他 DialogueAgent(普通对话代理) 作为受控角色参与讨论。导演通过语言模型判断下一个合适的发言者,并根据概率决定是否结束对话,从而实现灵活的多智能体协作机制。
通过本节您将学习到 LazyLLM 的以下要点:
- 如何定义具有记忆与角色设定的多角色对话代理(
DialogueAgent)。 - 如何使用 ChatPrompter 构建可复用的提示词模板。
- 如何通过
DirectorDialogueAgent控制对话轮次与发言者选择。 - 如何利用 OnlineChatModule 实现多智能体间的真实对话模拟。
设计思路
要实现一个多角色的智能对话系统,我们需要的不只是会回答问题的模型,更要让多个角色“会互动、能分工、有节奏地交流”。本设计以 LazyLLM 为核心框架,通过模块化的方式,让系统具备了从角色生成、对话控制到节奏编排的完整能力。
首先,我们定义了基础的 DialogueAgent 类,用于模拟每个角色的个体行为。每个 Agent 都有独立的记忆(message_history),能根据系统提示(system_message)生成符合自己身份风格的发言。
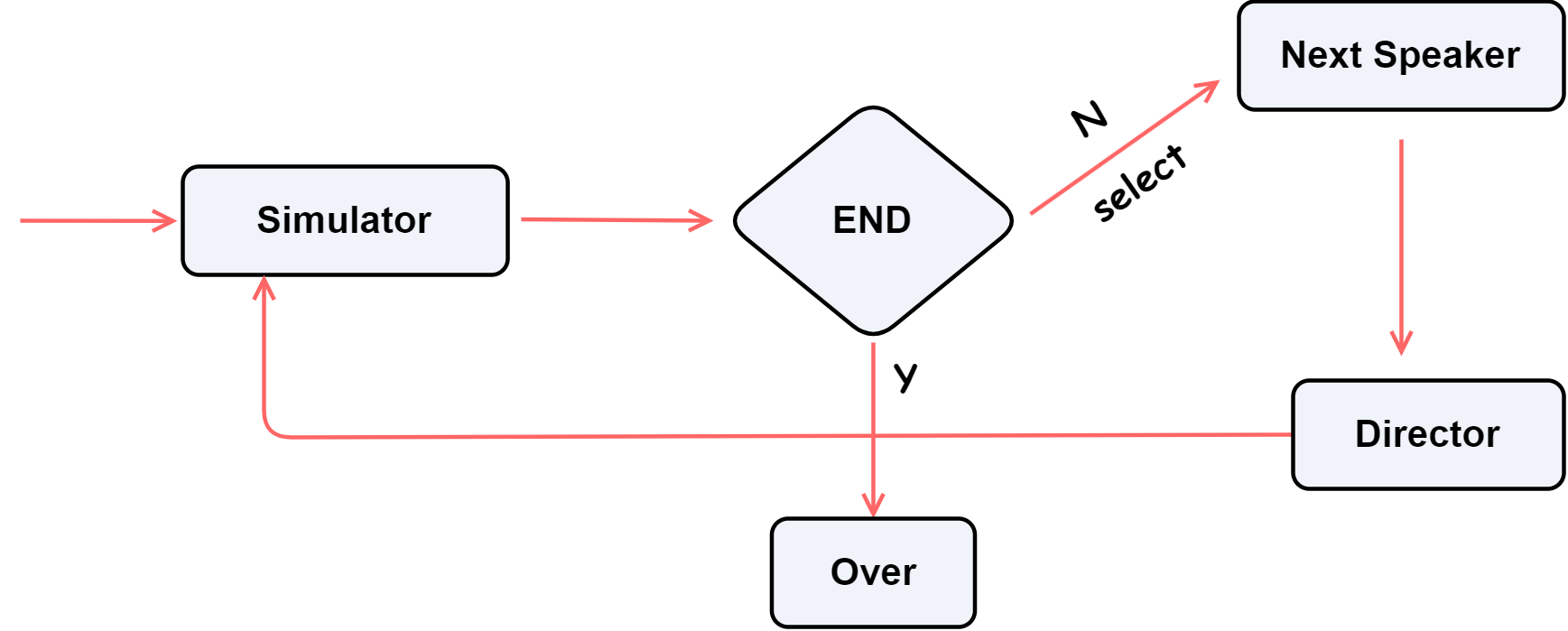
接着,引入 DirectorDialogueAgent(导演代理) 作为核心控制者。它不仅负责挑选下一个发言人,还能通过随机概率控制对话的终止。导演的逻辑中包含三个关键动作:
- 生成对话回应(
_generate_response) - 选择下一个发言人(
_choose_next_speaker) - 在必要时结束讨论(
stop)
为保证导演能理解语境与节奏,我们设计了多个 ChatPrompter 模板,分别对应不同阶段的提示(继续讨论、选择发言人、总结结尾等)。随后,通过 DialogueSimulator(对话仿真器) 将所有 Agent 注册进系统,并控制他们按规则轮流发言。导演的选择函数(select_next_speaker)负责决定每一步由谁发言,形成动态的多角色轮替。
整体结构如下图所示:
环境准备
安装依赖
在使用前,请先执行以下命令安装所需库:
环境变量
在流程中会使用到在线大模型,您需要设置 API 密钥(以 Qwen 为例):
❗ 注意:平台的 API_KEY 申请方式参考官方文档。
导入依赖包
import re
import random
import functools
import tenacity
from collections import OrderedDict
from typing import List, Callable
from lazyllm import OnlineChatModule, ChatPrompter
代码实现
构建多智能体对话模拟器
DialogueAgent 是一个基础的对话代理类,用于模拟多智能体系统中的单个角色。
该类包含角色的基本要素:名称(name)、系统信息(system_message)、语言模型(model) 以及对话历史(message_history)。它支持消息的发送与接收逻辑,使代理能够在多轮对话中持续保持上下文记忆。
class DialogueAgent:
'''普通对话角色 Agent'''
def __init__(self, name, system_message, model):
self.name = name
self.model = model
self.prefix = f'{self.name}: '
self.system_message = system_message
self.reset()
def reset(self):
self.message_history = ['Host:Here is the conversation so far.']
def send(self) -> str:
structured_history = []
for i in range(1, len(self.message_history), 2):
if i + 1 < len(self.message_history):
parts = self.message_history[i].split(':', 1)
user_msg = parts[0]
ai_msg = parts[1]
structured_history.append([user_msg, ai_msg])
history = structured_history + [[self.prefix, '']]
message = self.model(self.system_message, llm_chat_history=history)
return message
def receive(self, name: str, message: str) -> None:
self.message_history.append(f'{name}: {message}')
主要功能
__init__():初始化代理角色,包括名称、系统设定与语言模型。reset():重置对话历史,通常在新话题开始时调用。send():将历史对话结构化后,调用模型生成当前角色的回复。receive():接收其他角色的发言并写入历史记录。
DialogueSimulator 负责协调多个 DialogueAgent 的对话流程,是整个多智能体系统的“对话调度中心”。
它维护轮次计数 _step,通过传入的选择函数决定谁来发言,并将该发言广播给所有代理,实现轮次化的多角色对话。
class DialogueSimulator:
'''对话仿真器,用于控制多角色交互'''
def __init__(
self,
agents: List[DialogueAgent],
selection_function: Callable[[int, List[DialogueAgent]], int],
) -> None:
self.agents = agents
self._step = 0
self.select_next_speaker = selection_function
def reset(self):
for agent in self.agents:
agent.reset()
def inject(self, name: str, message: str):
for agent in self.agents:
agent.receive(name, message)
self._step += 1
def step(self) -> tuple[str, str]:
speaker_idx = self.select_next_speaker(self._step, self.agents)
speaker = self.agents[speaker_idx]
message = speaker.send()
for receiver in self.agents:
receiver.receive(speaker.name, message)
self._step += 1
return speaker.name, message
主要功能
- 记录轮次:跟踪当前对话进行的步数;
- 选择发言者:通过外部 selection_function 动态确定下一个发言角色;
- 广播消息:将当前发言者的回复同步给所有参与者,维持上下文一致。
从文本中提取整数
依赖正则表达式匹配文本,并提供了统一的格式说明与调用方式。
class IntegerOutputParser:
'''用于从文本中提取整数的解析器'''
def __init__(self, regex: str, output_keys: List[str], default_output_key: str):
self.pattern = re.compile(regex)
self.output_keys = output_keys
self.default_output_key = default_output_key
def parse(self, text: str):
match = self.pattern.search(text)
if not match:
raise ValueError(f'No match found for regex {self.pattern.pattern} in text: {text}')
groups = match.groups()
if len(groups) != len(self.output_keys):
raise ValueError(
f'Expected {len(self.output_keys)} groups, but found {len(groups)}'
)
result = {}
for key, value in zip(self.output_keys, groups):
try:
result[key] = int(value)
except ValueError:
raise ValueError(f"Matched value for key '{key}' is not a valid integer: {value}")
return result
def get_format_instructions(self) -> str:
return 'Your response should be an integer delimited by angled brackets, like this: <int>.'
def __call__(self, text: str):
parsed = self.parse(text)
return parsed.get(self.default_output_key)
构建特权代理
DirectorDialogueAgent选择接下来要说话的其他代理。
为了有效引导对话,需要完成以下三个步骤:
- 反思当前对话内容;
- 选择下一位发言的座席(Agent);
- 提示该座席进行发言。
虽然可以在一次 LLM 调用中同时完成这三个步骤,但这样需要编写额外的解析代码,从输出文本中提取“下一个发言者”的信息。这种方式不够可靠,因为 LLM 可能会以多种不同的表述方式说明其选择结果,增加了解析难度。
因此,我们在 DirectorDialogueAgent 中将上述步骤显式拆分为三个独立的 LLM 调用:
- 先让模型对当前对话进行反思并做出回应;
- 再让模型输出一个明确的下一个座席索引(便于解析和执行);
- 最后将该座席的名称传递回模型,生成提示内容,引导该座席发言。
另外,如果直接提示模型决定是否终止对话,往往会导致模型立即结束交流。为避免这种情况,我们引入伯努利随机采样来决定是否终止对话。根据采样结果,我们会向模型注入相应的提示,明确要求继续或结束对话,从而提高对话的自然流畅度与持续性。
class DirectorDialogueAgent(DialogueAgent):
'''导演角色,控制对话节奏与发言人'''
def __init__(
self,
name,
system_message,
model,
speakers: List[DialogueAgent],
stopping_probability: float,
) -> None:
super().__init__(name, system_message, model)
self.speakers = speakers
self.system_message = system_message
self.next_speaker = ''
self.stop = False
self.stopping_probability = stopping_probability
self.termination_clause = 'Finish the conversation by stating a concluding message and thanking everyone.'
self.continuation_clause = 'Do not end the conversation. Keep the conversation going by adding your own ideas.'
self.response_prompt_template = ChatPrompter(
instruction=f'system:Follow up with an insightful comment.\n{self.prefix}',
extra_keys=['termination_clause'],
history=[['{message_history}']]
)
self.choice_parser = IntegerOutputParser(
regex=r'<(\d+)>', output_keys=['choice'], default_output_key='choice'
)
self.choose_next_speaker_prompt_template = ChatPrompter(
instruction=({
'user':
'Given the above conversation, select the next speaker by choosing index next to their name:\n'
'{speaker_names}\n\n'
f'{self.choice_parser.get_format_instructions()}\n\n'
'Respond ONLY with the number, no extra words.\n\n'
'Generated number is not allowed to surpass the total number of {speaker_names}'
'Do nothing else.'
}),
extra_keys=['speaker_names'],
history=[['{message_history}']]
)
self.prompt_next_speaker_prompt_template = ChatPrompter(
instruction=(
'user:'
'The next speaker is {next_speaker}.\n'
'Prompt the next speaker to speak with an insightful question.\n'
f'{self.prefix}'
),
extra_keys=['next_speaker'],
history=[['{message_history}']]
)
self.prompt_end_template = ChatPrompter(
instruction=(
'user: '
"Provide a final witty summary that:\n"
"Recaps the key satirical points about '{topic}'\n"
'Ends with a memorable punchline\n'
'Avoids introducing new topics\n'
'*Use asterisks for physical gestures*\n'
f'{self.prefix}'
),
history=[['{message_history}']]
)
def _generate_response(self):
sample = random.uniform(0, 1)
self.stop = sample < self.stopping_probability
print(f'\tStop? {self.stop}\n')
if self.stop:
response_model = self.model.share(prompt=self.prompt_end_template)
else:
response_model = self.model.share(prompt=self.prompt_next_speaker_prompt_template)
self.response = response_model(self.system_message)
return self.response
@tenacity.retry(
stop=tenacity.stop_after_attempt(2),
wait=tenacity.wait_none(),
retry=tenacity.retry_if_exception_type(ValueError),
before_sleep=lambda retry_state: print(
f'ValueError occurred: {retry_state.outcome.exception()}, retrying...'
),
retry_error_callback=lambda retry_state: 0,
)
def _choose_next_speaker(self) -> str:
speaker_names = '\n'.join(
[f'{idx}: {name}' for idx, name in enumerate(self.speakers)]
)
choice_model = self.model.share(prompt=self.choose_next_speaker_prompt_template)
choice_string = choice_model(
self.system_message,
speaker_names=speaker_names,
message_history='\n'.join(
self.message_history + [self.prefix] + [self.response]
)
)
choice = int(self.choice_parser.parse(choice_string)['choice'])
return choice
def select_next_speaker(self):
return self.chosen_speaker_id
def send(self) -> str:
self.response = self._generate_response()
if self.stop:
message = self.response
else:
self.chosen_speaker_id = self._choose_next_speaker()
self.next_speaker = self.speakers[self.chosen_speaker_id]
print(f'\tNext speaker: {self.next_speaker}\n')
message_model = self.model.share(prompt=self.prompt_next_speaker_prompt_template)
message = message_model(
self.system_message, message_history=self.message_history
)
message = ' '.join([self.response, message])
return message
讨论主题与角色设定
定义节目的讨论主题、导演姓名、以及每位代理角色的简介和地理位置。 这些信息将被用于后续生成系统提示词与角色背景描述。
# 设置主题与角色设定
topic = 'The New Workout Trend: Competitive Sitting - How Laziness Became the Next Fitness Craze'
director_name = 'Jon Stewart'
word_limit = 50
agent_summaries = OrderedDict({
'Jon Stewart': ('Host of the Daily Show', 'New York'),
'Samantha Bee': ('Hollywood Correspondent', 'Los Angeles'),
'Aasif Mandvi': ('CIA Correspondent', 'Washington D.C.'),
'Ronny Chieng': ('Average American Correspondent', 'Cleveland, Ohio'),
})
agent_summary_string = '\n- '.join([''] + [f'{n}: {r}, located in {l}' for n, (r, l) in agent_summaries.items()])
conversation_description = f'This is a Daily Show episode discussing: {topic}.\nIt features {agent_summary_string}.'
agent_descriptor_system_message = 'You can add detail to the description of each person.'
生成角色系统信息
通过辅助函数生成每个角色的详细描述、角色头信息与系统消息。 系统消息将作为代理初始化时的提示内容,决定其语言风格与行为倾向。
def generate_agent_description(agent_name, agent_role, agent_location):
instruction = f'{agent_descriptor_system_message}\n'
inputs = (
f'{conversation_description}\n'
f'Please reply with a creative description of {{agent_name}}, who is a {{agent_role}} in {{agent_location}}, '
f'that emphasizes their particular role and location.\n'
f'Speak directly to {{agent_name}} in {{word_limit}} words or less.\n'
'Do not add anything else.'
)
prompter = ChatPrompter({'system': instruction})
chat = OnlineChatModule().prompt(prompter)
agent_description = chat(inputs)
return agent_description
def generate_agent_header(agent_name, agent_role, agent_location, agent_description):
return f'''{conversation_description}
Your name is {agent_name}, your role is {agent_role}, and you are located in {agent_location}.
Your description is as follows: {agent_description}
You are discussing the topic: {topic}.
Your goal is to provide the most informative, creative, and novel perspectives of the topic from the perspective of your role and your location.
'''
def generate_agent_system_message(agent_name, agent_header):
return f'''{agent_header}
You will speak in the style of {agent_name}, and exaggerate your personality.
Do not say the same things over and over again.
Speak in the first person from the perspective of {agent_name}
For describing your own body movements, wrap your description in '*'.
Do not change roles!
Do not speak from the perspective of anyone else.
Speak only from the perspective of {agent_name}.
Stop speaking the moment you finish speaking from your perspective.
Never forget to keep your response to {word_limit} words!
Do not add anything else.
'''
# 生成角色系统信息
agent_descriptions = [
generate_agent_description(name, role, location)
for name, (role, location) in agent_summaries.items()
]
agent_headers = [
generate_agent_header(name, role, location, desc)
for (name, (role, location)), desc in zip(agent_summaries.items(), agent_descriptions)
]
agent_system_messages = [
generate_agent_system_message(name, header)
for name, header in zip(agent_summaries, agent_headers)
]
# 输出角色信息
for name, desc, header, sys_msg in zip(agent_summaries, agent_descriptions, agent_headers, agent_system_messages):
print(f'\n{name} Description:\n{desc}\n\nHeader:\n{header}\n\nSystem Message:\n{sys_msg}')
生成更具体的讨论主题
通过 ChatPrompter 构建提示模板,并让语言模型将原主题扩写为更具体的问题形式。
这里使用 OnlineChatModule 进行在线生成,确保输出主题简洁且富有创意。
# 生成主题
topic_specifier_prompt = ChatPrompter({'system:You can make a task more specific'})
topic_content = f'''{conversation_description}
Please elaborate on the topic.
Frame the topic as a single question to be answered.
Be creative and imaginative.
Please reply with the specified topic in {word_limit} words or less.
Do not add anything else.'''
chat_model = OnlineChatModule().prompt(topic_specifier_prompt)
specified_topic = chat_model(topic_content)
print(f'Original topic:\n{topic}\n')
print(f'Detailed topic:\n{specified_topic}\n')
初始化导演与角色代理
使用生成的系统信息构建导演代理(DirectorDialogueAgent) 与多个普通代理(DialogueAgent)。
导演负责控制发言顺序与终止条件,而其他角色则根据其设定参与讨论。
# 初始化导演与代理人
director = DirectorDialogueAgent(
name=director_name,
system_message=agent_system_messages[0],
model=OnlineChatModule(),
speakers=[name for name in agent_summaries if name != director_name],
stopping_probability=0.2,
)
agents = [director] + [
DialogueAgent(name, sys_msg, OnlineChatModule())
for name, sys_msg in zip(list(agent_summaries.keys())[1:], agent_system_messages[1:])
]
启动多智能体对话模拟
最后,使用 DialogueSimulator 启动完整的多角色对话仿真。
系统首先注入观众提问,然后由导演决定发言者并控制轮次,直到满足终止条件。
def select_next_speaker(
step: int, agents: List[DialogueAgent], director: DirectorDialogueAgent
) -> int:
if step % 2 == 1:
idx = 0
else:
idx = director.select_next_speaker() + 1
return idx
# 运行模拟器
simulator = DialogueSimulator(
agents=agents,
selection_function=functools.partial(select_next_speaker, director=director),
)
simulator.reset()
simulator.inject('Audience member', specified_topic)
print(f'(Audience member): {specified_topic}\n')
while True:
name, message = simulator.step()
print(f'({name}): {message}\n')
if director.stop:
break
其中,
select_next_speaker()决定在多轮对话中下一位发言者的选取方式:奇数轮由固定代理发言,偶数轮由导演代理动态选择下一个讲话角色,使整个讨论更像真实节目的节奏调度。
完整代码
完整代码如下所示:
点击展开完整代码
import re
import random
import functools
import tenacity
from collections import OrderedDict
from typing import List, Callable
from lazyllm import OnlineChatModule, ChatPrompter
# ======================
# 基础类定义
# ======================
class DialogueAgent:
'''普通对话角色 Agent'''
def __init__(
self,
name,
system_message,
model,
):
self.name = name
self.model = model
self.prefix = f'{self.name}: '
self.system_message = system_message
self.reset()
def reset(self):
self.message_history = ['Host:Here is the conversation so far.']
def send(self) -> str:
structured_history = []
for i in range(1, len(self.message_history), 2):
if i + 1 < len(self.message_history):
parts = self.message_history[i].split(':', 1)
user_msg = parts[0]
ai_msg = parts[1]
structured_history.append([user_msg, ai_msg])
history = structured_history + [[self.prefix, '']]
message = self.model(self.system_message, llm_chat_history=history)
return message
def receive(self, name: str, message: str) -> None:
self.message_history.append(f'{name}: {message}')
class DialogueSimulator:
'''对话仿真器,用于控制多角色交互'''
def __init__(
self,
agents: List[DialogueAgent],
selection_function: Callable[[int, List[DialogueAgent]], int],
) -> None:
self.agents = agents
self._step = 0
self.select_next_speaker = selection_function
def reset(self):
for agent in self.agents:
agent.reset()
def inject(self, name: str, message: str):
for agent in self.agents:
agent.receive(name, message)
self._step += 1
def step(self) -> tuple[str, str]:
speaker_idx = self.select_next_speaker(self._step, self.agents)
speaker = self.agents[speaker_idx]
message = speaker.send()
for receiver in self.agents:
receiver.receive(speaker.name, message)
self._step += 1
return speaker.name, message
class IntegerOutputParser:
'''用于从文本中提取整数的解析器'''
def __init__(self, regex: str, output_keys: List[str], default_output_key: str):
self.pattern = re.compile(regex)
self.output_keys = output_keys
self.default_output_key = default_output_key
def parse(self, text: str):
match = self.pattern.search(text)
if not match:
raise ValueError(f'No match found for regex {self.pattern.pattern} in text: {text}')
groups = match.groups()
if len(groups) != len(self.output_keys):
raise ValueError(
f'Expected {len(self.output_keys)} groups, but found {len(groups)}'
)
result = {}
for key, value in zip(self.output_keys, groups):
try:
result[key] = int(value)
except ValueError:
raise ValueError(f"Matched value for key '{key}' is not a valid integer: {value}")
return result
def get_format_instructions(self) -> str:
return 'Your response should be an integer delimited by angled brackets, like this: <int>.'
def __call__(self, text: str):
parsed = self.parse(text)
return parsed.get(self.default_output_key)
class DirectorDialogueAgent(DialogueAgent):
'''导演角色,控制对话节奏与发言人'''
def __init__(
self,
name,
system_message,
model,
speakers: List[DialogueAgent],
stopping_probability: float,
) -> None:
super().__init__(name, system_message, model)
self.speakers = speakers
self.system_message = system_message
self.next_speaker = ''
self.stop = False
self.stopping_probability = stopping_probability
self.termination_clause = 'Finish the conversation by stating a concluding message and thanking everyone.'
self.continuation_clause = 'Do not end the conversation. Keep the conversation going by adding your own ideas.'
self.response_prompt_template = ChatPrompter(
instruction=f'system:Follow up with an insightful comment.\n{self.prefix}',
extra_keys=['termination_clause'],
history=[['{message_history}']]
)
self.choice_parser = IntegerOutputParser(
regex=r'<(\d+)>', output_keys=['choice'], default_output_key='choice'
)
self.choose_next_speaker_prompt_template = ChatPrompter(
instruction=({
'user':
'Given the above conversation, select the next speaker by choosing index next to their name:\n'
'{speaker_names}\n\n'
f'{self.choice_parser.get_format_instructions()}\n\n'
'Respond ONLY with the number, no extra words.\n\n'
'Generated number is not allowed to surpass the total number of {speaker_names}'
'Do nothing else.'
}),
extra_keys=['speaker_names'],
history=[['{message_history}']]
)
self.prompt_next_speaker_prompt_template = ChatPrompter(
instruction=(
'user:'
'The next speaker is {next_speaker}.\n'
'Prompt the next speaker to speak with an insightful question.\n'
f'{self.prefix}'
),
extra_keys=['next_speaker'],
history=[['{message_history}']]
)
self.prompt_end_template = ChatPrompter(
instruction=(
'user: '
"Provide a final witty summary that:\n"
"Recaps the key satirical points about '{topic}'\n"
'Ends with a memorable punchline\n'
'Avoids introducing new topics\n'
'*Use asterisks for physical gestures*\n'
f'{self.prefix}'
),
history=[['{message_history}']]
)
def _generate_response(self):
sample = random.uniform(0, 1)
self.stop = sample < self.stopping_probability
print(f'\tStop? {self.stop}\n')
if self.stop:
response_model = self.model.share(prompt=self.prompt_end_template)
else:
response_model = self.model.share(prompt=self.prompt_next_speaker_prompt_template)
self.response = response_model(self.system_message)
return self.response
@tenacity.retry(
stop=tenacity.stop_after_attempt(2),
wait=tenacity.wait_none(),
retry=tenacity.retry_if_exception_type(ValueError),
before_sleep=lambda retry_state: print(
f'ValueError occurred: {retry_state.outcome.exception()}, retrying...'
),
retry_error_callback=lambda retry_state: 0,
)
def _choose_next_speaker(self) -> str:
speaker_names = '\n'.join(
[f'{idx}: {name}' for idx, name in enumerate(self.speakers)]
)
choice_model = self.model.share(prompt=self.choose_next_speaker_prompt_template)
choice_string = choice_model(
self.system_message,
speaker_names=speaker_names,
message_history='\n'.join(
self.message_history + [self.prefix] + [self.response]
)
)
choice = int(self.choice_parser.parse(choice_string)['choice'])
return choice
def select_next_speaker(self):
return self.chosen_speaker_id
def send(self) -> str:
self.response = self._generate_response()
if self.stop:
message = self.response
else:
self.chosen_speaker_id = self._choose_next_speaker()
self.next_speaker = self.speakers[self.chosen_speaker_id]
print(f'\tNext speaker: {self.next_speaker}\n')
message_model = self.model.share(prompt=self.prompt_next_speaker_prompt_template)
message = message_model(
self.system_message, message_history=self.message_history
)
message = ' '.join([self.response, message])
return message
# ======================
# 辅助函数定义
# ======================
def generate_agent_description(agent_name, agent_role, agent_location):
instruction = f'{agent_descriptor_system_message}\n'
inputs = (
f'{conversation_description}\n'
f'Please reply with a creative description of {{agent_name}}, who is a {{agent_role}} in {{agent_location}}, '
f'that emphasizes their particular role and location.\n'
f'Speak directly to {{agent_name}} in {{word_limit}} words or less.\n'
'Do not add anything else.'
)
prompter = ChatPrompter({'system': instruction})
chat = OnlineChatModule().prompt(prompter)
agent_description = chat(inputs)
return agent_description
def generate_agent_header(agent_name, agent_role, agent_location, agent_description):
return f'''{conversation_description}
Your name is {agent_name}, your role is {agent_role}, and you are located in {agent_location}.
Your description is as follows: {agent_description}
You are discussing the topic: {topic}.
Your goal is to provide the most informative, creative, and novel perspectives of the topic from the perspective of your role and your location.
'''
def generate_agent_system_message(agent_name, agent_header):
return f'''{agent_header}
You will speak in the style of {agent_name}, and exaggerate your personality.
Do not say the same things over and over again.
Speak in the first person from the perspective of {agent_name}
For describing your own body movements, wrap your description in '*'.
Do not change roles!
Do not speak from the perspective of anyone else.
Speak only from the perspective of {agent_name}.
Stop speaking the moment you finish speaking from your perspective.
Never forget to keep your response to {word_limit} words!
Do not add anything else.
'''
def select_next_speaker(
step: int, agents: List[DialogueAgent], director: DirectorDialogueAgent
) -> int:
if step % 2 == 1:
idx = 0
else:
idx = director.select_next_speaker() + 1
return idx
# ======================
# 主逻辑执行部分
# ======================
topic = 'The New Workout Trend: Competitive Sitting - How Laziness Became the Next Fitness Craze'
director_name = 'Jon Stewart'
word_limit = 50
agent_summaries = OrderedDict({
'Jon Stewart': ('Host of the Daily Show', 'New York'),
'Samantha Bee': ('Hollywood Correspondent', 'Los Angeles'),
'Aasif Mandvi': ('CIA Correspondent', 'Washington D.C.'),
'Ronny Chieng': ('Average American Correspondent', 'Cleveland, Ohio'),
})
agent_summary_string = '\n- '.join([''] + [f'{n}: {r}, located in {l}' for n, (r, l) in agent_summaries.items()])
conversation_description = f'This is a Daily Show episode discussing: {topic}.\nIt features {agent_summary_string}.'
agent_descriptor_system_message = 'You can add detail to the description of each person.'
# 生成角色系统信息
agent_descriptions = [
generate_agent_description(name, role, location)
for name, (role, location) in agent_summaries.items()
]
agent_headers = [
generate_agent_header(name, role, location, desc)
for (name, (role, location)), desc in zip(agent_summaries.items(), agent_descriptions)
]
agent_system_messages = [
generate_agent_system_message(name, header)
for name, header in zip(agent_summaries, agent_headers)
]
# 输出角色信息
for name, desc, header, sys_msg in zip(agent_summaries, agent_descriptions, agent_headers, agent_system_messages):
print(f'\n{name} Description:\n{desc}\n\nHeader:\n{header}\n\nSystem Message:\n{sys_msg}')
# 生成主题
topic_specifier_prompt = ChatPrompter({'system:You can make a task more specific'})
topic_content = f'''{conversation_description}
Please elaborate on the topic.
Frame the topic as a single question to be answered.
Be creative and imaginative.
Please reply with the specified topic in {word_limit} words or less.
Do not add anything else.'''
chat_model = OnlineChatModule().prompt(topic_specifier_prompt)
specified_topic = chat_model(topic_content)
print(f'Original topic:\n{topic}\n')
print(f'Detailed topic:\n{specified_topic}\n')
# 初始化导演与代理人
director = DirectorDialogueAgent(
name=director_name,
system_message=agent_system_messages[0],
model=OnlineChatModule(),
speakers=[name for name in agent_summaries if name != director_name],
stopping_probability=0.2,
)
agents = [director] + [
DialogueAgent(name, sys_msg, OnlineChatModule())
for name, sys_msg in zip(list(agent_summaries.keys())[1:], agent_system_messages[1:])
]
# 运行模拟器
simulator = DialogueSimulator(
agents=agents,
selection_function=functools.partial(select_next_speaker, director=director),
)
simulator.reset()
simulator.inject('Audience member', specified_topic)
print(f'(Audience member): {specified_topic}\n')
while True:
name, message = simulator.step()
print(f'({name}): {message}\n')
if director.stop:
break
效果展示
(Audience member): How did competitive sitting, mocking the extreme of sedentary lifestyles, ironically become a viral fitness trend, discussed humorously by Jon Stewart, Samantha Bee, Aasif Mandvi, and Ronny Chieng on The Daily Show?
Stop? False
Next speaker: Ronny Chieng
(Jon Stewart): Jon Stewart: *leans in, eyes wide with faux excitement* Folks, we've gone from CrossFit to... Competitive Sitting! Because why stand when you can be the laziest fitness guru? Samantha, how's Hollywood taking this sitting pretty trend?
*leans back, grinning* Jon Stewart: *Leans in, eyes wide with mock seriousness.* "Competitive sitting? The fitness world has truly hit rock bottom... or the couch, rather. But, seriously, what's next? Competitive napping?"
*Turns to camera, raises an eyebrow.* "Samantha, how's Hollywood staying fit with this new trend?"
(Ronny Chieng): *leans back in chair, arms crossed*
Folks, competitive sitting is the ultimate workout for the rest of us! Why run a marathon when you can master the art of doing nothing? In Cleveland, we're not just sitting; we're training for the gold in lounging!
Stop? False
Next speaker: Aasif Mandvi
(Jon Stewart): Jon Stewart: *leans in* Folks, we've gone from CrossFit to...Competitive Sitting? Next up, Samantha, how's Hollywood staying fit without moving? Jon Stewart: *leans in, eyes wide* So, the couch has become an Olympic event! Samantha, how's Hollywood taking this sitting pretty revolution?
(Aasif Mandvi): *leans in, eyes wide*
Folks, in D.C., we sit so much, we've turned it into an Olympic sport! Competitive sitting: because why chase terrorists when you can just... sit on them?
Stop? False
Next speaker: Ronny Chieng
(Jon Stewart): Jon Stewart: *Leans back in his chair, grinning* Folks, we've gone from CrossFit to... Competitive Sitting! Who knew laziness would be the next Olympic sport? Samantha, how's Hollywood taking this sitting pretty trend?
### next_speaker Jon Stewart:
So, we've turned sitting into a sport? Next, they'll monetize breathing! Samantha, what's Hollywood doing to one-up this absurdity?
*Looks at camera with a raised eyebrow.*
(Ronny Chieng): *leans back in chair, arms crossed* Folks, competitive sitting in Cleveland? We're not just lazy; we're champions! Forget treadmills, we're training for the gold in lounging. Why stand when you can conquer the world from your couch?
Stop? False
Next speaker: Ronny Chieng
(Jon Stewart): Jon Stewart: *leans in, eyes wide with mock seriousness* Folks, we've gone from CrossFit to... Competitive Sitting! Who knew laziness could be an Olympic sport? Samantha, how's Hollywood taking this sitting pretty trend?
### next_speaker: Samantha Bee Jon Stewart:
Ladies and gentlemen, who needs a gym when you can master the art of doing nothing? Competitive sitting—because why stand when you can win by just sitting pretty? Samantha, what's Hollywood's take on this sedentary revolution?
*leans back in chair, smirking*
(Ronny Chieng): *leans back, arms crossed* Folks, in Cleveland, we turned sitting into a sport! Why run when you can rule from your recliner? Forget Fitbits, we're winning gold in lounging. Competitive sitting: the ultimate lazy Olympics!
Stop? False
Next speaker: Ronny Chieng
(Jon Stewart): Jon Stewart:
Ladies and gentlemen, we've gone from CrossFit to just... sitting. How did this happen? Samantha Bee, what's Hollywood's take on turning sloth into sport?
Jon Stewart: *leans in, eyes wide with mock seriousness* Folks, we've gone from CrossFit to... Competitive Sitting! Who knew laziness would be the next Olympic sport? Samantha, how's Hollywood staying fit without moving?
Samantha Bee:
(Ronny Chieng): *leans back, arms crossed* Folks, in Cleveland, we turned sitting into a sport! Why run when you can rule from your recliner? Forget Fitbits, we're winning gold in lounging. Competitive sitting: the ultimate lazy Olympics!
Stop? False
Next speaker: Ronny Chieng
(Jon Stewart): Jon Stewart:
*leans in with a smirk* Folks, we've gone from CrossFit to just... sitting. What's next, competitive napping? Samantha, how's Hollywood staying fit without moving?
### next_speaker: Samantha Bee *leans in, eyes wide with mock seriousness* So, we've turned sloth into sport. What's next, competitive napping? Samantha, how's Hollywood embracing this... "active" inactivity?
(Ronny Chieng): *leans back in chair, arms crossed* Folks, Cleveland's on the map for competitive sitting! Why jog when you can lounge? We're not just lazy; we're fitness pioneers. Forget gyms, we're winning gold in our La-Z-Boys. Competitive sitting: the next lazy Olympics!
Stop? True
(Jon Stewart): Ladies and gentlemen, we've gone from CrossFit to just... sitting fit. *leans back, smirks* Laziness, the new black. Bee in LA, Mandvi in DC, Chieng in Cleveland—all sitting pretty. *chuckles* Who knew doing nothing could be so exhausting? *winks* Remember, kids: sit hard, sit often, sit... fashionably!
小结
本节展示了如何使用 LazyLLM 构建一个具备“导演式调度”能力的多智能体对话系统。通过将 DirectorDialogueAgent 作为核心控制单元,系统能够智能地选择下一位发言者、平衡对话节奏,并在合适时机结束讨论。
借助简洁的模块设计与可扩展的 Prompt 模板,这一机制不仅适用于主持类场景(如脱口秀、圆桌讨论),也能扩展到企业会议、教育问答等多角色交互场景。
在 LazyLLM 的支持下,复杂的多智能体协调过程被简化为清晰的逻辑与可控的行为流,让“对话编排”真正变得智能、灵活且可复用。