构建你的第一个聊天机器人
让我们以一个经典的聊天机器人来开始对 LazyLLM 的探索之旅吧。
通过本节您将学习到 LazyLLM 的以下要点
- TrainableModule 和 OnlineChatModule 的使用,以实现线下线上模型的部署;
- 通过 WebModule 来实现网页客户端的发布;
- 如何指定一个模型;
- 如何设置 history。
三行代码构建聊天机器人
问:用LazyLLM构建一个聊天机器人,总共分几步?
答:三步!
- 导入
lazyllm; - 指定要用的模型;
- 启动客户端。
效果如下:
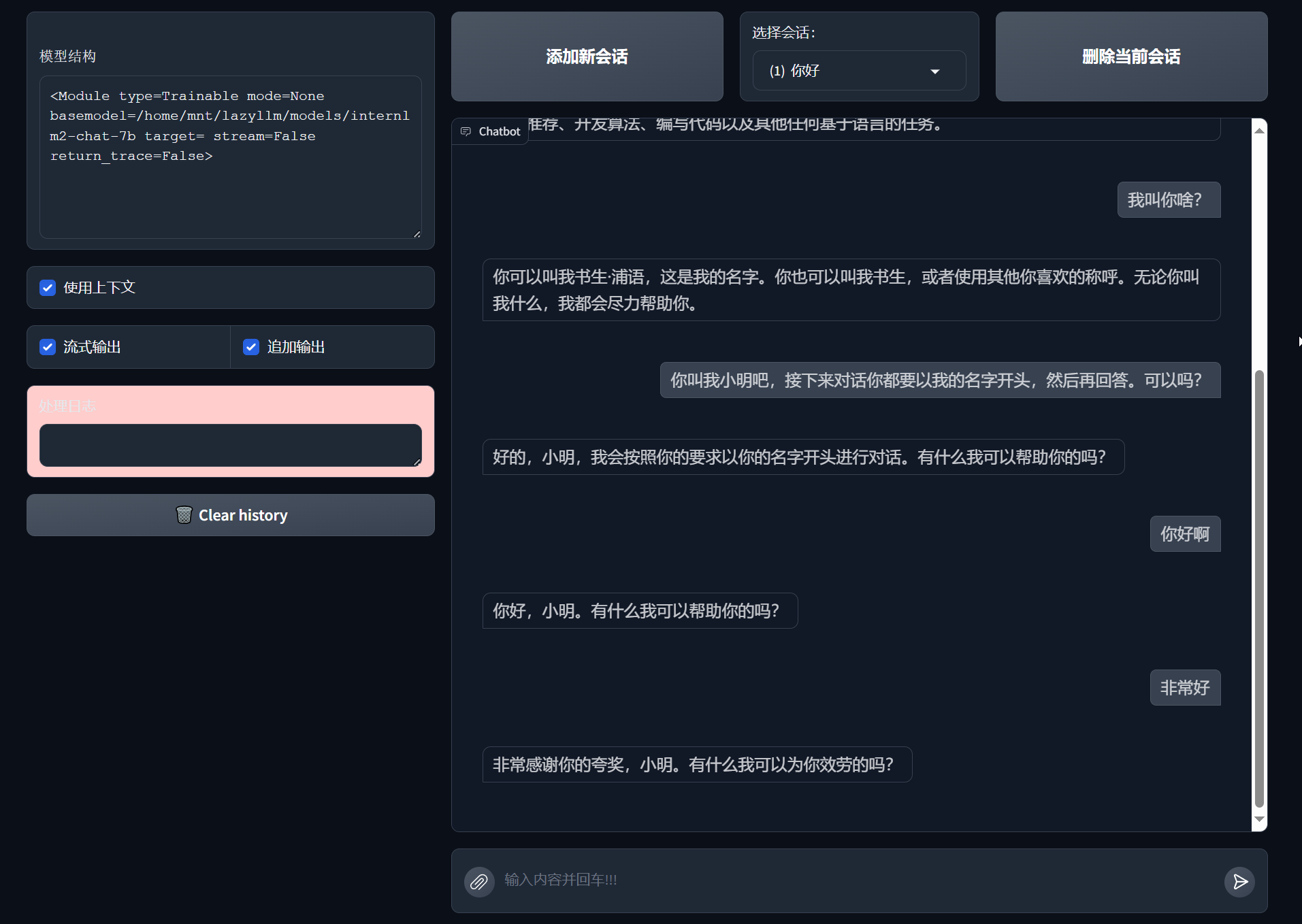
是的,就这么简单!下面就是构建聊天机器人的三行代码:
import lazyllm
chat = lazyllm.TrainableModule('internlm2-chat-7b')
lazyllm.WebModule(chat, port=23466).start().wait()
让我们来详细解释一下吧。
指定模型
1. 本地模型
- TrainableModule 是 LazyLLM 的一个核心模块,这个模块功能十分强大,可以进行预训练、微调、和模型部署。 这里我们只涉及到它的部署功能。使用它的时候至少要指定一个模型名。
internlm2-chat-7b是我们这个例子用到的模型。在LazyLLM中有三种方式可以指定模型。- 指定模型具体的名字(例如这里的:'internlm2-chat-7b'):LazyLLM会从网络上自动下载该模型;
- 指定模型具体的名字(例如这里的:'internlm2-chat-7b')+ 设置环境变量
export LAZYLLM_MODEL_PATH="/path/to/modelzoo": 此时LazyLLM会从path/to/modelazoo/internlm2-chat-7b/来找到模型; - 直接使用模型的绝对路径:
path/to/modelazoo/internlm2-chat-7b。
2. 线上模型
source: 指定要访问的模型来源。选项包括 openai / sensenova / glm / kimi / qwen / 豆包等。model: 指定要访问的模型(注意,使用豆包时需要使用模型ID或端点ID。获取方法,请参见获取推理接入点。在使用模型之前,必须先在豆包平台上开通相应的服务),默认为 gpt-3.5-turbo(openai) / SenseChat-5(sensenova) / glm-4(glm) / moonshot-v1-8k(kimi) / qwen-plus(qwen) / mistral-7b-instruct-v0.2(doubao)。
❗ 注意:在使用线上模型时需要配置 API_KEY,参考 LazyLLM 官方文档(平台支持部分)。
启动模型
- WebModule 是 LazyLLM 的另一个核心模块, 它可以将任何可调用的东西包装为一个客户端。 包装的效果就如一开始的展示所示。被包装的东西作为第一个参数传入它,这里就是将我们的一个可部署的模型chat,给它给套了个客户端的壳子。
port用于指定客户端发布的端口。这里port是可以省略的,如果不指定的话LazyLLM会从20500到20799找一个未被占用的端口来使用,我们也可以自己指定一个可用的端口范围。start在 LazyLLM 中十分关键,是启动的意思。如果start一旦执行,就会把整个应用中所有模块的部署都跑一遍。 这里 TrainableModule 和 WebModule 会部署一个internlm2-chat-7b模型,并启动一个Web客户端。wait用于在客户端启动后就让它保持一直开启而不关闭。
部署完成并且客户端启动后,LazyLLM 会在终端打印可访问的URL。
多轮对话聊天机器人
细心的读者应该发现了,在上面demo的图示中,聊天机器人是具有记忆功能的,它能进行多轮对话。现在让我们基于上一节的单论对话机器人进行改造,让它可以进行多轮对话吧。
指定history
在 WebModule 中指定 history 参数,修改如下:
import lazyllm
chat = lazyllm.TrainableModule('internlm2-chat-7b')
lazyllm.WebModule(chat, port=23466, history=[chat]).start().wait()
history 是一个记忆列表,列表中指定了把上下文传给谁。这里是传给了 chat。
开启使用上下文
history 的指定是开启上下文的第一步。在使用客户端的时候,还要开启上下文功能,才能保证记忆功能打开。如下:
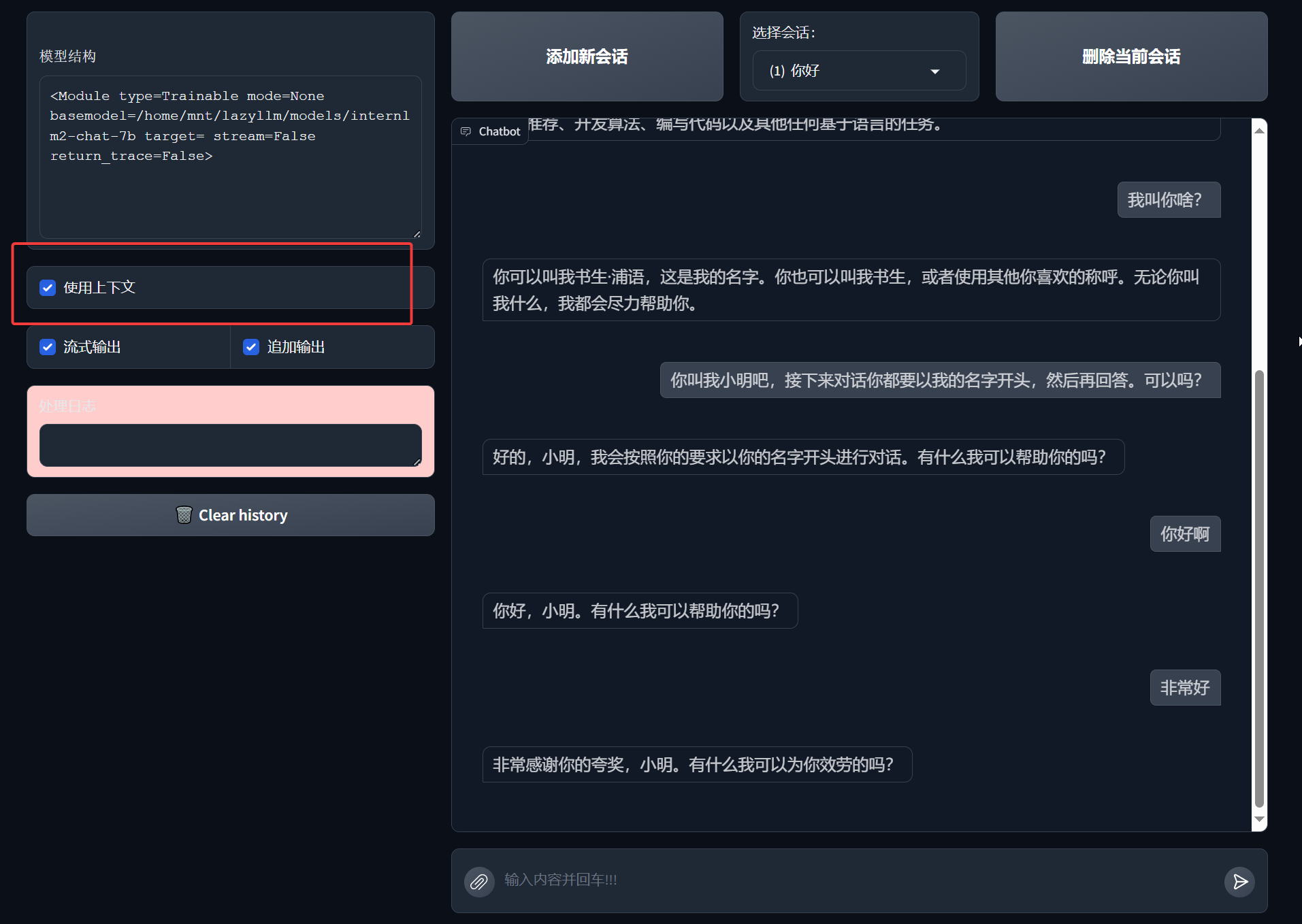
至此,我们的第一个聊天机器人就创建好了!让我们和它开始畅聊吧!