AI编程与LazyLLM
0. 文档说明
文档目录
- 1. 前言
- 2. 安装OpenCode
- 3. 安装LazyLLM
- 4. 安装LazyLLM-Skill
- 5. OpenCode+LazyLLM-Skill的基本使用方式
- 6. 快速开发AI应用
- 7. 常见问题与排错
- 8. 结语
教程目标
本教程旨在帮助读者使用OpenCode 与 LazyLLM-Skill,在不写一行业务代码的前提下,快速构建可运行的AI应用与AI Agent项目。
通过本教程,你将学会:
-
如何安装并使用OpenCode作为AI开发入口
-
如何安装并启用LazyLLM-Skill
-
如何通过自然语言描述需求,让OpenCode基于LazyLLM自动生成项目代码
适用人群
本教程适合以下几类读者:
-
希望尝试AI应用开发,但不熟悉复杂框架与工程细节的初学者
-
具备一定编程经验,希望快速验证想法、搭建原型的开发者
-
正在关注Agent、RAG、AI Workflow等方向,希望了解低门槛实现路径的工程人员
-
想体验AI编程助手 + Skill新型开发方式的技术爱好者
不要求具备大模型底层原理或复杂算法背景。 只要具备基础的计算机使用能力,能按照教程步骤操作,即可完成全部内容。
1. 前言
真正可落地的AI应用远不止调用模型接口。从数据准备、模型微调、RAG知识库构建,到Agent智能体编排,每个环节都涉及复杂的工程化问题。
LazyLLM是面向生产级AI应用的一站式开发框架,覆盖模型微调训练、流程编排、RAG、Agent等完整链路。其核心设计哲学是声明式开发——用简洁的代码描述复杂的工作流,让工程师专注于业务逻辑而非基础设施。
为了让零基础用户快速落地AI应用,可以结合OpenCode和lazyllm-skill实现自然语言开发。它将LazyLLM的大部分能力封装为开箱即用的Skill模块(如文档问答、代码助手、搜索 Agent 等),支持大部分AI编程助手一键式安装,用户只需关心自己的业务逻辑,无需关心模型加载、向量数据库等底层细节,像搭积木一样即可构建复杂应用。
现在让我们从安装OpenCode和LazyLLM-Skill开始,一起快速上手LazyLLM开发,实现自己的第一个AI应用。
2. 安装OpenCode
我们这里介绍OpenCode在Windows和Mac/Linux上的安装步骤。
2.1 Windows 安装
- Windows安装需要依赖Node.js
Node.js安装流程:
- 打开浏览器访问 https://nodejs.org/
- 点击 "LTS" 版本进行下载(推荐长期支持版本)
- 下载完成后双击 .msi 文件
- 按照安装向导完成安装,保持默认设置即可
- 验证Node.js流程: 安装完成后,打开 PowerShell 或 CMD,输入以下命令,如果显示版本号,说明安装成功了:
- 安装OpenCode 打开 PowerShell 或 CMD(推荐PwerShell,功能会更强),运行以下命令,这个命令会从npm官方仓库下载并安装最新版本的OpenCode:
2.2 Mac / Linux 安装
打开终端或者在terminal中输入以下命令直接安装:
2.3 验证安装
安装完成后,输入以下命令检查是否安装成功:
如果显示版本号,说明安装成功了。
3. 安装LazyLLM
AI 编程助手就绪后,接下来部署LazyLLM框架本体。LazyLLM基于Python开发,安装与环境配置都可以一行命令完成。
3.1 安装 Python
LazyLLM需要大于等于3.10版本的Python,如果环境中已经有了满足条件的Python,直接跳过这一步。
-
Windows安装
可以从官网下载 ,也可以直接从Miscrosoft Store下载。
-
Macos安装
命令行内输入如下命令即可完成安装:
Python 就绪后,建议创建独立的虚拟环境,避免依赖冲突。
3.2 创建虚拟环境
虚拟环境可以隔离项目依赖,确保 LazyLLM 的运行环境干净可控。 创建一个名为lazyllm-venv的虚拟环境
激活这个虚拟环境
环境激活后,即可在隔离空间中安装 LazyLLM 及其依赖。
3.3 安装 LazyLLM
进入虚拟环境,使用 pip 一键安装 LazyLLM 核心库。
其他安装方式可以参考LazyLLM安装中开发环境搭建部分的内容 安装完成后,还需配置模型服务商的 API Key,才能调用底层大模型能力。
API Key的申请和配置可以参考API配置中API Key部分的内容。
4. 安装LazyLLM-Skill
这里以上面安装的OpenCode编程助手为例,演示如何一键安装LazyLLM-Skill。
-
4.1 全局安装
全局安装LazyLLM-Skill可以让OpenCode在所有项目都能使用该Skill,命令如下:

-
4.2 项目级安装
如果只希望在某个项目中使用LazyLLM-Skill,可以在项目目录下执行以下命令安装:

-
4.3 LazyLLM-Skill 支持的AI编程助手
目前LazyLLM-Skill不仅支持OpenCode,支持一键安装市面上主流的大部分AI编程助手。
编程助手名称 Claude Code OpenCode Codex Gemini Qwen Copilot Cursor Qoder Zencoder Clawdbot 代码 claude opencode codex gemini qwen copilot cursor qoder zencoder clawdbot 只需将安装命令中的
opencode替换为对应的编程助手代码即可。
5. 基本使用方式
现在我们可以开始使用OpenCode和LazyLLM-Skill来开发自己的AI应用了。 首先我们先介绍一下OpenCode的基本使用方法
5.1 OpenCode的使用
-
启动OpenCode 输入以下命令启动OpenCode:
等待OpenCode启动完成,会在终端显示OpenCode的界面。
-
OpenCode的相关命令 按下
Ctrl + P可以查看OpenCode的全部命令。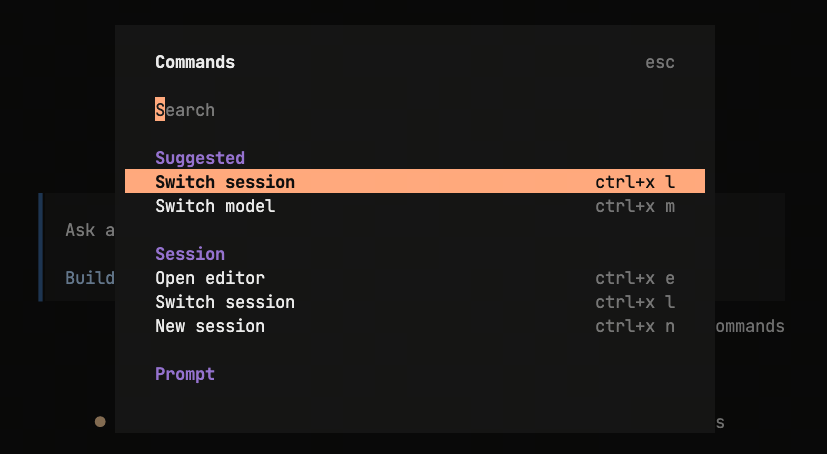 主要使用的命令有:
主要使用的命令有:/models:切换模型/sessions:切换不同会话/new:创建新会话/connect:连接自定义模型供应商
-
基本操作
- build模式:
在OpenCode界面中输入自己的任务需求,按下
Enter键。生成的代码会保存在当前文件夹中,用户可以根据需要进行修改。 - plan模式
在OpenCode界面中输入自己的问题,按下
Enter键。OpenCode会根据问题生成一个任务计划,用户可以根据计划进行开发。
- build模式:
在OpenCode界面中输入自己的任务需求,按下
5.2 使用 LazyLLM-Skill 的核心原则
-
安装LazyLLM-Skill 确保已经安装了LazyLLM-Skill,具体安装方法可以参考安装LazyLLM-Skill。
-
配置模型服务商的 API Key 确保已经配置了模型服务商的 API Key,具体配置方法可以参考API配置中API Key部分的内容。
-
输入要求 在OpenCode界面中输入自己的任务需求是,必须包含lazyllm或LazyLLM字段,否则OpenCode不会调用LazyLLM-Skill。 示例: *
请用LazyLLM实现一个简单的RAG程序*使用LazyLLM实现一个代码Agent,并使用graido实现web前端交互,用户输入需求生成相应代码后可以下载使用
5.3 快速开发AI应用
我们使用OpenCode+LazyLLM-Skill来实现一个论文助手,用户上传论文后,助手根据用户输入的问题,从论文在提取相关信息并回答。
启动OpenCode,在对话框内输入使用LazyLLM实现一个论文助手,要求用户可以上传论文,助手根据用户输入的问题,从论文中提取相关信息并回答,按下Enter键。
OpenCode会根据需求生成一个如下自带web界面的RAG程序,用户可以根据需要进行修改。
# -*- coding: utf-8 -*-
"""
论文助手 - 基于LazyLLM的RAG论文问答系统
支持上传论文,根据用户问题从论文中提取相关信息并回答
"""
import os
import tempfile
import lazyllm
from lazyllm.tools.rag import SentenceSplitter
class PaperAssistant:
def __init__(self, embed_model=None, llm_model=None):
"""
初始化论文助手
Args:
embed_model: 向量模型,默认使用在线Embedding
llm_model: 大语言模型,默认使用在线Chat模型
"""
self.embed_model = embed_model or lazyllm.OnlineEmbeddingModule()
self.llm_model = llm_model or lazyllm.OnlineChatModule()
self.documents = None
self.retriever = None
self.reranker = None
self.rag_func = None
self.paper_dir = tempfile.mkdtemp()
self._setup_prompt()
def _setup_prompt(self):
"""设置提示词"""
self.prompt = """你是一位专业的论文助手,负责根据论文内容回答用户的问题。
任务要求:
1. 仔细阅读并理解用户的问题
2. 从提供的论文上下文中找到相关信息
3. 基于论文内容给出准确、详细的回答
4. 如果问题在论文中没有明确提及,请明确说明
论文上下文:
{context_str}
用户问题:{query}
请根据以上论文内容回答用户问题。如果需要引用论文中的具体内容,请使用引号标注。"""
def upload_paper(self, file_path):
"""
上传并处理论文
Args:
file_path: 论文文件路径(支持PDF、Markdown、TXT等格式)
"""
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件不存在: {file_path}")
file_name = os.path.basename(file_path)
dest_path = os.path.join(self.paper_dir, file_name)
with open(file_path, 'rb') as src_file:
with open(dest_path, 'wb') as dst_file:
dst_file.write(src_file.read())
self.documents = lazyllm.Document(
dataset_path=self.paper_dir,
embed=self.embed_model,
manager=False
)
self.documents.create_node_group(
name="sentences",
transform=SentenceSplitter(chunk_size=1024, chunk_overlap=100)
)
self.retriever = lazyllm.Retriever(
doc=self.documents,
group_name="sentences",
similarity="cosine",
topk=5
)
self.reranker = lazyllm.Reranker(
name='ModuleReranker',
model=lazyllm.OnlineEmbeddingModule(type="rerank"),
topk=3
)
self._build_rag_func()
return f"论文《{file_name}》已成功上传并处理!"
def _build_rag_func(self):
"""构建RAG处理函数"""
llm = self.llm_model
prompt = self.prompt
llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
def rag_func(query):
nodes = self.retriever(query=query)
if self.reranker:
nodes = self.reranker(nodes=nodes, query=query)
context_str = "".join([node.get_content() for node in nodes])
return llm({"query": query, "context_str": context_str})
self.rag_func = rag_func
def ask(self, question):
"""
提问
Args:
question: 用户问题
Returns:
str: 基于论文内容的回答
"""
if not self.documents:
return "请先上传论文文件!"
if not self.rag_func:
return "系统正在初始化,请稍后再试!"
try:
result = self.rag_func(question)
return result
except Exception as e:
return f"处理问题时出错: {str(e)}"
def get_paper_info(self):
"""获取已上传论文的信息"""
if not self.documents:
return "尚未上传论文"
files = os.listdir(self.paper_dir)
return f"已上传论文: {', '.join(files)}"
def create_web_interface():
"""创建Web界面"""
import gradio as gr
assistant = PaperAssistant()
def upload_file(file):
try:
result = assistant.upload_paper(file.name)
info = assistant.get_paper_info()
return result, info
except Exception as e:
return f"上传失败: {str(e)}", "上传失败"
def answer_question(question):
if not question.strip():
return "请输入问题!"
response = assistant.ask(question)
return response
with gr.Blocks(title="论文助手") as demo:
gr.Markdown("# 论文助手")
gr.Markdown("基于LazyLLM的RAG论文问答系统,支持上传论文并根据内容回答问题")
with gr.Row():
with gr.Column(scale=1):
file_input = gr.File(
label="上传论文",
file_types=[".pdf", ".md", ".txt"],
type="filepath"
)
upload_btn = gr.Button("上传并处理", variant="primary")
upload_status = gr.Markdown("")
paper_info = gr.Markdown("")
with gr.Column(scale=2):
question_input = gr.Textbox(
label="输入问题",
placeholder="例如:这篇论文的主要贡献是什么?",
lines=3
)
submit_btn = gr.Button("提问", variant="secondary")
answer_output = gr.Textbox(
label="回答结果",
placeholder="回答将显示在这里...",
lines=10
)
upload_btn.click(
fn=upload_file,
inputs=file_input,
outputs=[upload_status, paper_info]
)
submit_btn.click(
fn=answer_question,
inputs=question_input,
outputs=answer_output
)
return demo
def run_command_line():
"""命令行交互模式"""
print("=" * 60)
print("论文助手 - 基于LazyLLM的RAG论文问答系统")
print("=" * 60)
assistant = PaperAssistant()
while True:
print("\n请选择操作:")
print("1. 上传论文")
print("2. 提问")
print("3. 查看已上传论文")
print("4. 退出")
choice = input("请输入选项 (1-4): ").strip()
if choice == "1":
file_path = input("请输入论文文件路径: ").strip()
try:
result = assistant.upload_paper(file_path)
print(f"\n{result}")
except Exception as e:
print(f"\n上传失败: {str(e)}")
elif choice == "2":
if not assistant.documents:
print("\n请先上传论文!")
continue
question = input("请输入问题: ").strip()
if question:
print("\n正在分析论文...")
answer = assistant.ask(question)
print(f"\n回答:\n{answer}")
elif choice == "3":
print(f"\n{assistant.get_paper_info()}")
elif choice == "4":
print("\n感谢使用论文助手,再见!")
break
else:
print("\n无效选项,请重新选择!")
if __name__ == "__main__":
import sys
if len(sys.argv) > 1 and sys.argv[1] == "--web":
print("启动Web界面...")
demo = create_web_interface()
demo.launch(server_name="0.0.0.0", server_port=7860)
else:
run_command_line()
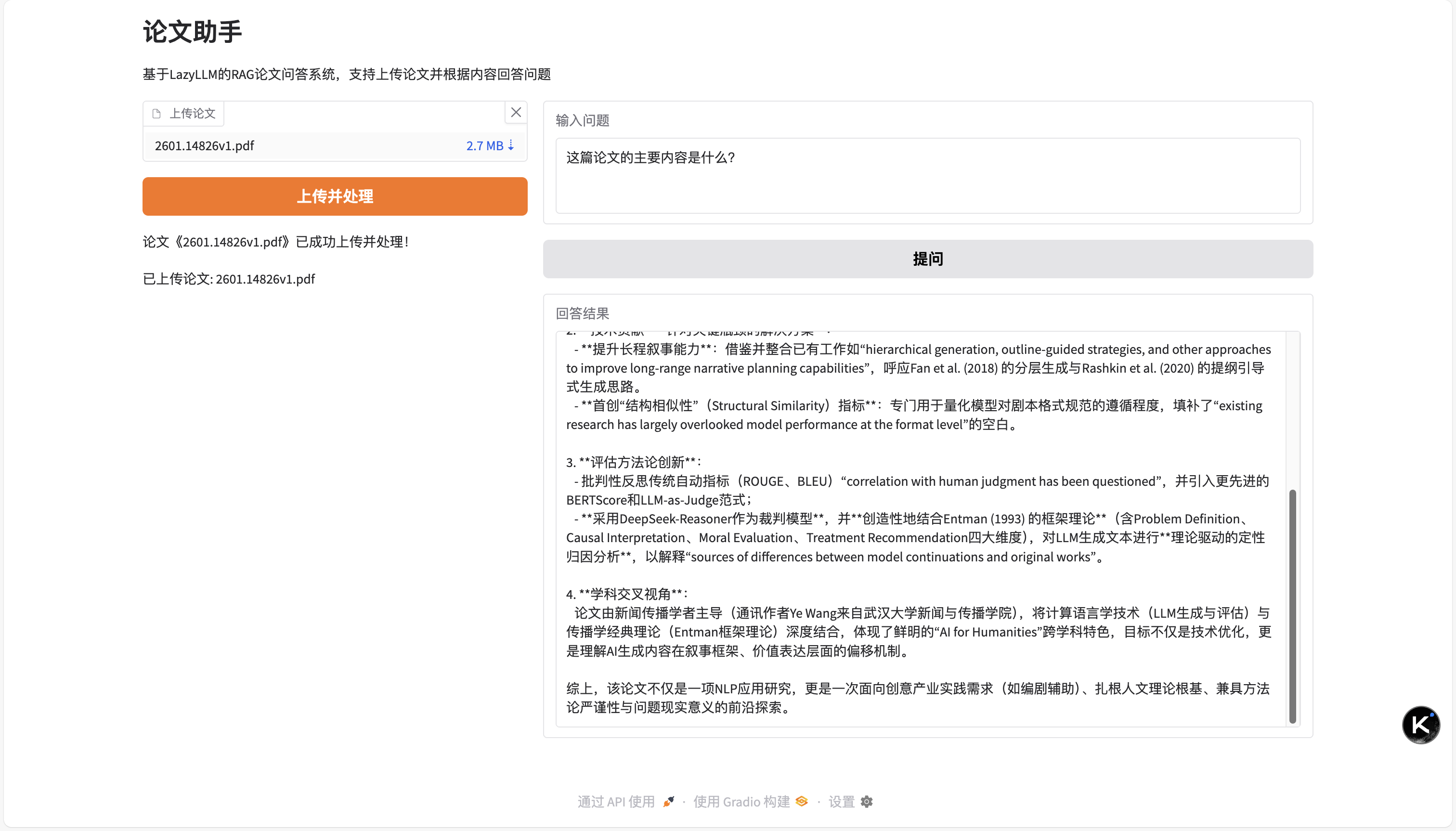
我们启动程序后便得到如下Web界面,上传论文后,助手会处理论文内容,并据此给出问题回答。
6. 示例应用
6.1 示例一:生成简易RAG程序
prompt:
import lazyllm
# 1. 创建文档对象,加载知识库
documents = lazyllm.Document(
dataset_path="./LazyLLM/docs",
embed=lazyllm.OnlineEmbeddingModule(),
manager=False
)
# 2. 创建检索器
retriever = lazyllm.Retriever(
doc=documents,
group_name="CoarseChunk",
similarity="bm25_chinese",
topk=3
)
# 3. 创建大语言模型
llm = lazyllm.OnlineChatModule()
prompt = '根据上下文回答问题:'
llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
# 4. 执行 RAG 流程
if __name__ == '__main__':
query = "LazyLLM 是什么?"
doc_node_list = retriever(query=query)
res = llm({
"query": query,
"context_str": "".join([node.get_content() for node in doc_node_list]),
})
print(f"问题: {query}")
print(f"回答: {res}")
6.2 示例二:自定义切分策略的RAG程序
prompt:
在./LazyLLM/example2.py文件内使用lazyllm实现一个RAG,要求按照字符'。'进行切分,切分长度不超过512,使用cosine相似度,并且召回数量不超过两个,我可以从命令行进行交互,知识库文档在./LazyLLM/docs
import lazyllm
# 1. 创建文档对象,加载知识库
documents = lazyllm.Document(
dataset_path="./LazyLLM/docs",
embed=lazyllm.OnlineEmbeddingModule(),
manager=False
)
# 2. 创建自定义切分节点组,按照'。'切分,切分长度不超过512
documents.create_node_group(
name="sentence_chunk",
transform=lambda s: [chunk for chunk in s.split('。') if chunk],
chunk_size=512
)
# 3. 创建检索器,使用cosine相似度,召回数量不超过2个
retriever = lazyllm.Retriever(
doc=documents,
group_name="sentence_chunk",
similarity="cosine",
topk=2
)
# 4. 创建大语言模型
llm = lazyllm.OnlineChatModule()
prompt = '根据上下文回答问题:'
llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
# 5. 命令行交互
if __name__ == '__main__':
print("=== RAG 问答系统 ===")
print("输入问题进行查询,输入 'quit' 或 'exit' 退出")
print("-" * 30)
while True:
query = input("\n请输入问题: ").strip()
if query.lower() in ['quit', 'exit', 'q']:
print("再见!")
break
if not query:
print("问题不能为空,请重新输入")
continue
# 执行检索
doc_node_list = retriever(query=query)
# 生成回答
res = llm({
"query": query,
"context_str": "".join([node.get_content() for node in doc_node_list]),
})
print(f"\n回答: {res}")
print("-" * 30)
6.3 示例三:自定义存储后端的RAG程序
prompt:
在./LazyLLM/example3.py中使用lazyllm实现一个rag功能,要求使用chroma作为存储后端,index时HNSW,已知文档内容多是json内容,选择合适的切分器,要求使用重排序,最后只输出一个召回结果,并且根据召回结果回答问题,我可以从命令行进行交互,参考文档路径:./LazyLLM/docs
import lazyllm
from lazyllm.tools.rag import JSONSplitter
# 1. 配置 Chroma 存储后端 + HNSW 索引
store_conf = {
'segment_store': {
'type': 'map',
'kwargs': {
'uri': './segment_store.db',
},
},
'vector_store': {
'type': 'chroma',
'kwargs': {
'dir': './chroma_db',
'index_kwargs': {
'hnsw': {
'space': 'cosine',
'ef_construction': 200,
}
}
},
},
}
# 2. 创建文档对象,加载知识库
documents = lazyllm.Document(
dataset_path="./LazyLLM/docs",
embed=lazyllm.OnlineEmbeddingModule(),
store_conf=store_conf,
manager=False
)
# 3. 创建 JSON 切分节点组
documents.create_node_group(
name="json_chunk",
transform=JSONSplitter(chunk_size=512, chunk_overlap=50)
)
# 4. 创建检索器
retriever = lazyllm.Retriever(
doc=documents,
group_name="json_chunk",
similarity="cosine",
topk=5
)
# 5. 创建重排序器,只保留最相关的一个结果
reranker = lazyllm.Reranker(
name='ModuleReranker',
model=lazyllm.OnlineEmbeddingModule(type="rerank"),
topk=1
)
# 6. 创建大语言模型
llm = lazyllm.OnlineChatModule()
prompt = '根据上下文回答问题,如果上下文不足以回答问题,请说明无法回答:'
llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
# 7. 命令行交互
if __name__ == '__main__':
print("=== RAG 问答系统 (Chroma + HNSW + JSON切分 + 重排序) ===")
print("输入问题进行查询,输入 'quit' 或 'exit' 退出")
print("-" * 50)
while True:
query = input("\n请输入问题: ").strip()
if query.lower() in ['quit', 'exit', 'q']:
print("再见!")
break
if not query:
print("问题不能为空,请重新输入")
continue
# 执行检索
doc_node_list = retriever(query=query)
if not doc_node_list:
print("\n未检索到相关文档")
continue
# 执行重排序,只保留最相关的一个结果
reranked_nodes = reranker(nodes=doc_node_list, query=query)
if not reranked_nodes:
print("\n重排序后无有效结果")
continue
# 获取召回的文档内容
context_str = reranked_nodes[0].get_content()
print(f"\n召回的文档片段: {context_str[:200]}...")
print("-" * 50)
# 生成回答
res = llm({
"query": query,
"context_str": context_str,
})
print(f"\n回答: {res}")
print("-" * 50)
6.4 示例四:生成复杂流程和配置的RAG程序
prompt:
在文件./LazyLLM/example4.py中使用lazyllm实现一个复杂rag,要求使用三个知识库,分别使用内存存储,chroma存储,内存存储和chroma混合存储;每个知识库召回一个,然后使用重排序,最后只输出一个结果给大模型。我可以用命令后进行交互,知识库文档全部使用/./LazyLLM/docs。
import lazyllm
# ==================== 配置三个知识库的存储后端 ====================
# 1. 内存存储配置(MapStore)
memory_store_conf = {
'type': 'map',
'kwargs': {
'uri': './memory_segment.db',
}
}
# 2. Chroma 存储配置 + HNSW 索引
chroma_store_conf = {
'segment_store': {
'type': 'map',
'kwargs': {
'uri': './chroma_segment.db',
},
},
'vector_store': {
'type': 'chroma',
'kwargs': {
'dir': './chroma_vector_db',
'index_kwargs': {
'hnsw': {
'space': 'cosine',
'ef_construction': 200,
}
}
},
},
}
# 3. 混合存储配置(内存 + Chroma)
hybrid_store_conf = {
'segment_store': {
'type': 'map',
'kwargs': {
'uri': './hybrid_segment.db',
},
},
'vector_store': {
'type': 'chroma',
'kwargs': {
'dir': './hybrid_chroma_db',
'index_kwargs': {
'hnsw': {
'space': 'cosine',
'ef_construction': 200,
}
}
},
},
}
# ==================== 创建三个知识库 ====================
# 使用相同的嵌入模型
embed_model = lazyllm.OnlineEmbeddingModule()
# 知识库 1:内存存储
doc_memory = lazyllm.Document(
dataset_path="./LazyLLM/docs",
embed=embed_model,
store_conf=memory_store_conf,
manager=False
)
# 知识库 2:Chroma 存储
doc_chroma = lazyllm.Document(
dataset_path="./LazyLLM/docs",
embed=embed_model,
store_conf=chroma_store_conf,
manager=False
)
# 知识库 3:混合存储(内存 + Chroma)
doc_hybrid = lazyllm.Document(
dataset_path="./LazyLLM/docs",
embed=embed_model,
store_conf=hybrid_store_conf,
manager=False
)
# ==================== 创建三个检索器(每个召回1个) ====================
retriever_memory = lazyllm.Retriever(
doc=doc_memory,
group_name="CoarseChunk",
similarity="cosine",
topk=1
)
retriever_chroma = lazyllm.Retriever(
doc=doc_chroma,
group_name="CoarseChunk",
similarity="cosine",
topk=1
)
retriever_hybrid = lazyllm.Retriever(
doc=doc_hybrid,
group_name="CoarseChunk",
similarity="cosine",
topk=1
)
# ==================== 创建重排序器(只保留最相关的一个) ====================
reranker = lazyllm.Reranker(
name='ModuleReranker',
model=lazyllm.OnlineEmbeddingModule(type="rerank"),
topk=1
)
# ==================== 创建大语言模型 ====================
llm = lazyllm.OnlineChatModule()
prompt = '根据上下文回答问题,如果上下文不足以回答问题,请说明无法回答:'
llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
# ==================== 命令行交互 ====================
if __name__ == '__main__':
print("=== 复杂 RAG 问答系统(三知识库 + 重排序) ===")
print("存储后端:内存存储 | Chroma存储 | 混合存储(内存+Chroma)")
print("输入问题进行查询,输入 'quit' 或 'exit' 退出")
print("-" * 60)
while True:
query = input("\n请输入问题: ").strip()
if query.lower() in ['quit', 'exit', 'q']:
print("再见!")
break
if not query:
print("问题不能为空,请重新输入")
continue
print("\n正在从三个知识库检索...")
# 从三个知识库分别检索,每个召回1个结果
result_memory = retriever_memory(query=query)
result_chroma = retriever_chroma(query=query)
result_hybrid = retriever_hybrid(query=query)
# 合并所有检索结果
all_results = []
if result_memory:
all_results.extend(result_memory)
print(f"✓ 内存存储: 召回 {len(result_memory)} 个结果")
else:
print("✗ 内存存储: 无结果")
if result_chroma:
all_results.extend(result_chroma)
print(f"✓ Chroma存储: 召回 {len(result_chroma)} 个结果")
else:
print("✗ Chroma存储: 无结果")
if result_hybrid:
all_results.extend(result_hybrid)
print(f"✓ 混合存储: 召回 {len(result_hybrid)} 个结果")
else:
print("✗ 混合存储: 无结果")
if not all_results:
print("\n所有知识库均未检索到相关文档")
continue
print(f"\n总计召回 {len(all_results)} 个结果,正在进行重排序...")
# 执行重排序,只保留最相关的一个结果
reranked_nodes = reranker(nodes=all_results, query=query)
if not reranked_nodes:
print("\n重排序后无有效结果")
continue
# 获取最相关的文档内容
best_result = reranked_nodes[0]
context_str = best_result.get_content()
print(f"\n最佳召回结果(来自重排序): {context_str[:150]}...")
print("-" * 60)
# 生成回答
res = llm({
"query": query,
"context_str": context_str,
})
print(f"\n回答: {res}")
print("-" * 60)
6.5 示例五:生成具有Web界面交互的RAG程序
prompt:
帮我在./LazyLLM/example5.py使用lazyllm实现一个复杂rag应用,要求使用三个知识库,分别使用内存存储,chroma向量存储,混合存储,各召回一个结果,使用重排序召回一个结果,要求用一个web界面进行交互。知识库文档都使用./LazyLLM/docs
"""
复杂RAG应用示例 - 使用三个知识库和重排序
- 知识库1: 内存存储 (MapStore)
- 知识库2: Chroma向量存储
- 知识库3: 混合存储 (MapStore + Chroma)
- 使用重排序优化结果
- Web界面交互
"""
import lazyllm
from lazyllm import bind
# ==================== 配置部分 ====================
# 文档路径
DATASET_PATH = "./LazyLLM/docs"
# 存储路径配置
MEMORY_STORE_PATH = "./LazyLLM/stores/memory"
CHROMA_STORE_PATH = "./LazyLLM/stores/chroma"
HYBRID_STORE_PATH = "./LazyLLM/stores/hybrid"
# 嵌入模型 (使用在线嵌入模型,也可以使用本地模型)
EMBED_MODEL = lazyllm.OnlineEmbeddingModule()
# 重排序模型
RERANK_MODEL = lazyllm.OnlineEmbeddingModule(type="rerank")
# 大语言模型
LLM_MODEL = lazyllm.OnlineChatModule()
# ==================== 存储配置 ====================
# 1. 内存存储配置 (仅使用MapStore)
memory_store_conf = {
'segment_store': {
'type': 'map',
'kwargs': {
'uri': f'{MEMORY_STORE_PATH}/segments.db',
},
},
}
# 2. Chroma向量存储配置
chroma_store_conf = {
'type': 'chroma',
'kwargs': {
'dir': f'{CHROMA_STORE_PATH}/vectors',
'index_kwargs': {
'hnsw': {
'space': 'cosine',
'ef_construction': 200,
}
}
},
}
# 3. 混合存储配置 (MapStore + Chroma)
hybrid_store_conf = {
'segment_store': {
'type': 'map',
'kwargs': {
'uri': f'{HYBRID_STORE_PATH}/segments.db',
},
},
'vector_store': {
'type': 'chroma',
'kwargs': {
'dir': f'{HYBRID_STORE_PATH}/vectors',
'index_kwargs': {
'hnsw': {
'space': 'cosine',
'ef_construction': 200,
}
}
},
},
}
# ==================== 创建知识库 ====================
print("正在初始化三个知识库...")
# 知识库1: 内存存储 (使用MapStore)
doc_memory = lazyllm.Document(
dataset_path=DATASET_PATH,
embed=EMBED_MODEL,
store_conf=memory_store_conf,
manager=False
)
# 知识库2: Chroma向量存储
doc_chroma = lazyllm.Document(
dataset_path=DATASET_PATH,
embed=EMBED_MODEL,
store_conf=chroma_store_conf,
manager=False
)
# 知识库3: 混合存储
doc_hybrid = lazyllm.Document(
dataset_path=DATASET_PATH,
embed=EMBED_MODEL,
store_conf=hybrid_store_conf,
manager=False
)
# 创建节点组 - 句子级别切分
def split_sentences(text):
return text.split('。')
# 为每个知识库创建句子级别的节点组
doc_memory.create_node_group(name="sentences", transform=split_sentences)
doc_chroma.create_node_group(name="sentences", transform=split_sentences)
doc_hybrid.create_node_group(name="sentences", transform=split_sentences)
print("知识库初始化完成!")
# ==================== 构建RAG流程 ====================
prompt_template = '''你是一个专业的人工智能助手。请根据以下上下文回答问题。
上下文信息:
{context_str}
用户问题:{query}
请基于上下文提供准确、简洁的回答。如果上下文不包含相关信息,请明确说明。'''
with lazyllm.pipeline() as ppl:
# 并行检索 - 从三个知识库各召回1个结果
with lazyllm.parallel().sum as ppl.prl:
# 检索器1: 内存存储 + BM25
ppl.prl.retriever_memory = lazyllm.Retriever(
doc=doc_memory,
group_name="CoarseChunk",
similarity="bm25_chinese",
topk=1
)
# 检索器2: Chroma向量存储 + 余弦相似度
ppl.prl.retriever_chroma = lazyllm.Retriever(
doc=doc_chroma,
group_name="CoarseChunk",
similarity="cosine",
topk=1
)
# 检索器3: 混合存储 + 句子级别BM25
ppl.prl.retriever_hybrid = lazyllm.Retriever(
doc=doc_hybrid,
group_name="sentences",
similarity="bm25_chinese",
topk=1
)
# 重排序 - 从3个结果中选择最相关的1个
ppl.reranker = lazyllm.Reranker(
name='ModuleReranker',
model=RERANK_MODEL,
topk=1
) | bind(query=ppl.input)
# 格式化上下文
ppl.formatter = (
lambda nodes, query: dict(
context_str="".join([node.get_content() for node in nodes]),
query=query,
)
) | bind(query=ppl.input)
# 大语言模型生成回答
ppl.llm = LLM_MODEL.prompt(
lazyllm.ChatPrompter(
instruction=prompt_template,
extra_keys=['context_str']
)
)
# 创建ActionModule
rag_module = lazyllm.ActionModule(ppl)
# ==================== Web界面 ====================
print("正在启动Web服务...")
# 创建Web界面
web_module = lazyllm.WebModule(
rag_module,
port=8080,
title="复杂RAG问答系统"
)
# 启动服务
web_module.start()
print(f"\n{'='*60}")
print("RAG Web服务已启动!")
print(f"访问地址: http://localhost:8080")
print(f"{'='*60}")
print("\n系统特点:")
print("1. 内存存储知识库 - 使用BM25检索")
print("2. Chroma向量存储知识库 - 使用余弦相似度检索")
print("3. 混合存储知识库 - 使用句子级BM25检索")
print("4. 重排序优化 - 从三个结果中选择最相关的")
print("\n按 Ctrl+C 停止服务")
# 保持程序运行
try:
import time
while True:
time.sleep(1)
except KeyboardInterrupt:
print("\n正在停止服务...")
web_module.stop()
print("服务已停止")
6.6 示例六:生成一个代码Agent
prompt:
"""
代码 Agent 示例
使用 lazyllm 实现一个能够执行代码、搜索代码、读写文件的智能体
"""
import lazyllm
from lazyllm.tools import fc_register, ReactAgent
import subprocess
import os
@fc_register("tool")
def execute_python(code: str) -> str:
"""
执行 Python 代码并返回结果。
Args:
code (str): 要执行的 Python 代码字符串
Returns:
str: 代码执行结果或错误信息
"""
try:
# 使用 subprocess 执行代码,增加安全性
result = subprocess.run(
['python', '-c', code],
capture_output=True,
text=True,
timeout=30
)
if result.returncode == 0:
return f"执行成功:\n{result.stdout}"
else:
return f"执行错误:\n{result.stderr}"
except subprocess.TimeoutExpired:
return "执行超时(超过30秒)"
except Exception as e:
return f"执行异常: {str(e)}"
@fc_register("tool")
def search_code(query: str, path: str = ".") -> str:
"""
在指定目录下搜索包含关键字的代码文件。
Args:
query (str): 搜索关键字
path (str): 搜索路径,默认为当前目录
Returns:
str: 匹配的文件列表
"""
try:
matches = []
for root, dirs, files in os.walk(path):
# 跳过隐藏目录和常见非代码目录
dirs[:] = [d for d in dirs if not d.startswith('.') and d not in ['node_modules', '__pycache__', 'venv', '.git']]
for file in files:
if file.endswith(('.py', '.js', '.ts', '.java', '.cpp', '.c', '.h', '.go', '.rs', '.md')):
file_path = os.path.join(root, file)
try:
with open(file_path, 'r', encoding='utf-8', errors='ignore') as f:
content = f.read()
if query in content:
matches.append(file_path)
except:
continue
if matches:
return f"找到 {len(matches)} 个匹配文件:\n" + "\n".join(matches[:10]) # 最多返回10个
else:
return f"未找到包含 '{query}' 的文件"
except Exception as e:
return f"搜索错误: {str(e)}"
@fc_register("tool")
def read_file(file_path: str) -> str:
"""
读取指定文件的内容。
Args:
file_path (str): 文件路径
Returns:
str: 文件内容或错误信息
"""
try:
if not os.path.exists(file_path):
return f"文件不存在: {file_path}"
with open(file_path, 'r', encoding='utf-8', errors='ignore') as f:
content = f.read()
# 限制返回内容长度
if len(content) > 5000:
content = content[:5000] + "\n... (内容已截断,共 {} 字符)".format(len(content))
return content
except Exception as e:
return f"读取错误: {str(e)}"
@fc_register("tool")
def write_file(file_path: str, content: str) -> str:
"""
将内容写入指定文件。
Args:
file_path (str): 文件路径
content (str): 要写入的内容
Returns:
str: 操作结果
"""
try:
# 确保目录存在
directory = os.path.dirname(file_path)
if directory and not os.path.exists(directory):
os.makedirs(directory)
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
return f"成功写入文件: {file_path}"
except Exception as e:
return f"写入错误: {str(e)}"
@fc_register("tool")
def list_files(path: str = ".") -> str:
"""
列出指定目录下的文件和文件夹。
Args:
path (str): 目录路径,默认为当前目录
Returns:
str: 文件列表
"""
try:
if not os.path.exists(path):
return f"路径不存在: {path}"
items = os.listdir(path)
files = []
dirs = []
for item in items:
item_path = os.path.join(path, item)
if os.path.isdir(item_path):
dirs.append(f"[DIR] {item}")
else:
files.append(f"[FILE] {item}")
result = []
if dirs:
result.append("文件夹:")
result.extend(dirs)
if files:
result.append("\n文件:")
result.extend(files)
return "\n".join(result) if result else "目录为空"
except Exception as e:
return f"列出错误: {str(e)}"
# 定义可用的工具列表
tools = [
"execute_python", # 执行 Python 代码
"search_code", # 搜索代码
"read_file", # 读取文件
"write_file", # 写入文件
"list_files" # 列出文件
]
# 创建 LLM 模型
# 使用在线模型(需要配置 API Key)
# llm = lazyllm.OnlineChatModule(source="openai", model="gpt-4")
# 或使用其他在线模型
llm = lazyllm.OnlineChatModule(source="deepseek", model="deepseek-chat")
# 或者使用本地模型(需要提前部署)
# llm = lazyllm.TrainableModule("internlm2-chat-20b").deploy_method(lazyllm.deploy.vllm).start()
# 创建 ReactAgent
agent = ReactAgent(
llm=llm,
tools=tools,
max_retries=5,
return_trace=True # 返回详细执行轨迹,便于调试
)
if __name__ == "__main__":
# 示例查询
queries = [
"计算 123 的平方根",
"列出当前目录下的所有文件",
"搜索包含 'ReactAgent' 的代码文件",
]
print("=" * 60)
print("代码 Agent 示例")
print("=" * 60)
for query in queries:
print(f"\n用户: {query}")
print("-" * 40)
try:
result = agent(query)
print(f"Agent: {result}")
except Exception as e:
print(f"错误: {str(e)}")
print("=" * 60)
# 交互模式
print("\n进入交互模式(输入 'exit' 退出):")
while True:
user_input = input("\n用户: ").strip()
if user_input.lower() in ['exit', 'quit', '退出']:
print("再见!")
break
if not user_input:
continue
try:
result = agent(user_input)
print(f"Agent: {result}")
except Exception as e:
print(f"错误: {str(e)}")
6.7 示例七:生成一个简易AI编程助手Agent
prompt:
在./LazyLLM/example7.py中使用lazyllm实现一个代码agent,支持读取文件、写代码、执行验证代码,具备上下文管理和命令行交互能力,支持模型切换。知识库文档在./LazyLLM/docs
"""
代码Agent示例 - 支持读取文件、写代码、执行验证代码
具备上下文管理和命令行交互能力,支持模型切换
"""
import os
import sys
import json
import subprocess
import lazyllm
from lazyllm.tools import fc_register, FunctionCallAgent
from lazyllm import OnlineChatModule
# ==================== 工具函数定义 ====================
@fc_register('tool')
def read_file(file_path: str) -> str:
"""
读取指定文件的内容。
Args:
file_path (str): 文件的绝对路径或相对路径
Returns:
str: 文件内容,如果文件不存在则返回错误信息
"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
return f"文件内容:\n```\n{content}\n```"
except FileNotFoundError:
return f"错误: 文件 '{file_path}' 不存在"
except Exception as e:
return f"错误: 读取文件时发生异常: {str(e)}"
@fc_register('tool')
def write_file(file_path: str, content: str) -> str:
"""
将内容写入指定文件。如果文件已存在,会覆盖原有内容。
Args:
file_path (str): 文件的绝对路径或相对路径
content (str): 要写入文件的内容
Returns:
str: 操作结果信息
"""
try:
# 确保目录存在
directory = os.path.dirname(file_path)
if directory and not os.path.exists(directory):
os.makedirs(directory)
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
return f"成功: 内容已写入文件 '{file_path}'"
except Exception as e:
return f"错误: 写入文件时发生异常: {str(e)}"
@fc_register('tool')
def execute_code(code: str, language: str = "python") -> str:
"""
执行指定的代码并返回执行结果。支持 Python 和 Bash 脚本。
Args:
code (str): 要执行的代码
language (str): 编程语言,可选 "python" 或 "bash",默认为 "python"
Returns:
str: 代码执行结果,包括标准输出、标准错误和返回码
"""
try:
if language.lower() == "python":
# 执行 Python 代码
result = subprocess.run(
[sys.executable, "-c", code],
capture_output=True,
text=True,
timeout=30
)
elif language.lower() == "bash":
# 执行 Bash 脚本
result = subprocess.run(
code,
shell=True,
capture_output=True,
text=True,
timeout=30
)
else:
return f"错误: 不支持的语言 '{language}',目前仅支持 python 和 bash"
output = []
if result.stdout:
output.append(f"标准输出:\n{result.stdout}")
if result.stderr:
output.append(f"标准错误:\n{result.stderr}")
output.append(f"返回码: {result.returncode}")
return "\n".join(output)
except subprocess.TimeoutExpired:
return "错误: 代码执行超时(超过30秒)"
except Exception as e:
return f"错误: 执行代码时发生异常: {str(e)}"
@fc_register('tool')
def list_files(directory: str = ".") -> str:
"""
列出指定目录下的文件和子目录。
Args:
directory (str): 目录路径,默认为当前目录
Returns:
str: 目录内容列表
"""
try:
items = os.listdir(directory)
files = []
dirs = []
for item in items:
full_path = os.path.join(directory, item)
if os.path.isdir(full_path):
dirs.append(f"[DIR] {item}")
else:
files.append(f"[FILE] {item}")
result = []
if dirs:
result.append("目录:")
result.extend(sorted(dirs))
if files:
result.append("\n文件:")
result.extend(sorted(files))
return "\n".join(result) if result else "目录为空"
except Exception as e:
return f"错误: 无法列出目录内容: {str(e)}"
# ==================== 模型管理类 ====================
class ModelManager:
"""模型管理器,支持切换不同的在线模型"""
# 支持的模型配置
SUPPORTED_MODELS = {
"deepseek": {"source": "deepseek", "model": "deepseek-chat"},
"openai": {"source": "openai", "model": "gpt-4"},
"glm": {"source": "glm", "model": "glm-4"},
"sensenova": {"source": "sensenova", "model": "SenseChat"},
"kimi": {"source": "kimi", "model": "moonshot-v1-8k"},
}
def __init__(self, default_model: str = "deepseek"):
self.current_model_name = default_model
self.current_llm = self._create_llm(default_model)
self.chat_history = []
def _create_llm(self, model_name: str):
"""创建指定模型的 LLM 实例"""
if model_name not in self.SUPPORTED_MODELS:
raise ValueError(f"不支持的模型: {model_name}")
config = self.SUPPORTED_MODELS[model_name]
model = config.get("model")
if model is None:
model = ""
return OnlineChatModule(source=config["source"], model=model)
def switch_model(self, model_name: str) -> str:
"""切换到指定的模型"""
try:
if model_name not in self.SUPPORTED_MODELS:
available = ", ".join(self.SUPPORTED_MODELS.keys())
return f"错误: 不支持的模型 '{model_name}'。可用模型: {available}"
self.current_llm = self._create_llm(model_name)
self.current_model_name = model_name
# 切换模型时清空历史记录
self.chat_history = []
return f"成功切换到模型: {model_name}"
except Exception as e:
return f"切换模型失败: {str(e)}"
def get_current_model(self):
"""获取当前模型实例"""
return self.current_llm
def get_model_name(self) -> str:
"""获取当前模型名称"""
return self.current_model_name
def add_to_history(self, query: str, response: str):
"""添加对话到历史记录"""
self.chat_history.append([query, response])
def get_history(self):
"""获取对话历史"""
return self.chat_history
def clear_history(self):
"""清空对话历史"""
self.chat_history = []
return "对话历史已清空"
# ==================== 代码Agent类 ====================
class CodeAgent:
"""代码Agent,支持文件操作、代码执行和交互"""
def __init__(self, model_manager: ModelManager):
self.model_manager = model_manager
self.tools = ["read_file", "write_file", "execute_code", "list_files"]
self.agent = None
self._create_agent()
def _create_agent(self):
"""创建 FunctionCallAgent 实例"""
llm = self.model_manager.get_current_model()
self.agent = FunctionCallAgent(llm, tools=self.tools)
def process_query(self, query: str) -> str:
"""处理用户查询"""
# 如果模型已切换,重新创建agent
if self.agent is None:
self._create_agent()
if self.agent is None:
return "错误: Agent初始化失败"
# 执行查询
response = self.agent(query)
# 添加到历史记录
self.model_manager.add_to_history(query, response)
return response
def on_model_switched(self):
"""模型切换后的回调"""
self._create_agent()
# ==================== 命令行交互界面 ====================
class InteractiveCLI:
"""交互式命令行界面"""
def __init__(self):
self.model_manager = ModelManager()
self.code_agent = CodeAgent(self.model_manager)
self.running = True
def print_help(self):
"""打印帮助信息"""
help_text = """
╔══════════════════════════════════════════════════════════════╗
║ 代码Agent 交互控制台 ║
╠══════════════════════════════════════════════════════════════╣
║ 命令: ║
║ /help - 显示此帮助信息 ║
║ /models - 列出可用模型 ║
║ /switch <模型名> - 切换到指定模型 ║
║ /model - 显示当前模型 ║
║ /history - 显示对话历史 ║
║ /clear - 清空对话历史 ║
║ /exit 或 /quit - 退出程序 ║
╠══════════════════════════════════════════════════════════════╣
║ 可用工具: ║
║ • read_file - 读取文件内容 ║
║ • write_file - 写入文件内容 ║
║ • execute_code- 执行代码(Python/Bash) ║
║ • list_files - 列出目录内容 ║
╠══════════════════════════════════════════════════════════════╣
║ 提示: ║
║ 直接输入问题或指令即可与Agent交互 ║
║ 支持多轮对话,Agent会记住上下文 ║
╚══════════════════════════════════════════════════════════════╝
"""
print(help_text)
def list_models(self):
"""列出可用模型"""
print("\n可用模型:")
for name, config in ModelManager.SUPPORTED_MODELS.items():
current = " (当前)" if name == self.model_manager.get_model_name() else ""
print(f" • {name}: {config['source']} - {config['model']}{current}")
print()
def switch_model(self, model_name: str):
"""切换模型"""
result = self.model_manager.switch_model(model_name)
print(result)
if "成功" in result:
self.code_agent.on_model_switched()
def show_current_model(self):
"""显示当前模型"""
print(f"\n当前模型: {self.model_manager.get_model_name()}")
config = ModelManager.SUPPORTED_MODELS.get(self.model_manager.get_model_name())
if config:
print(f" 来源: {config['source']}")
print(f" 模型: {config['model']}")
print()
def show_history(self):
"""显示对话历史"""
history = self.model_manager.get_history()
if not history:
print("\n暂无对话历史\n")
return
print("\n" + "="*60)
print("对话历史:")
print("="*60)
for i, (query, response) in enumerate(history, 1):
print(f"\n[{i}] 用户: {query}")
print(f"[{i}] Agent: {response[:200]}{'...' if len(response) > 200 else ''}")
print("\n" + "="*60 + "\n")
def clear_history(self):
"""清空对话历史"""
result = self.model_manager.clear_history()
print(result)
def process_command(self, command: str) -> bool:
"""处理命令,返回是否继续运行"""
command = command.strip()
if not command:
return True
# 检查是否为命令
if command.startswith("/"):
parts = command[1:].split(maxsplit=1)
cmd = parts[0].lower()
arg = parts[1] if len(parts) > 1 else ""
if cmd in ["exit", "quit"]:
print("再见!")
return False
elif cmd == "help":
self.print_help()
elif cmd == "models":
self.list_models()
elif cmd == "switch":
if arg:
self.switch_model(arg.strip())
else:
print("请指定模型名,例如: /switch deepseek")
elif cmd == "model":
self.show_current_model()
elif cmd == "history":
self.show_history()
elif cmd == "clear":
self.clear_history()
else:
print(f"未知命令: /{cmd},输入 /help 查看帮助")
else:
# 普通查询,交给Agent处理
print("\nAgent思考中...")
try:
response = self.code_agent.process_query(command)
print(f"\nAgent: {response}\n")
except Exception as e:
print(f"\n错误: {str(e)}\n")
return True
def run(self):
"""运行交互式CLI"""
self.print_help()
while self.running:
try:
# 显示提示符
prompt = f"[{self.model_manager.get_model_name()}] > "
user_input = input(prompt).strip()
self.running = self.process_command(user_input)
except KeyboardInterrupt:
print("\n\n检测到中断,退出程序...")
break
except EOFError:
print("\n再见!")
break
except Exception as e:
print(f"\n发生错误: {str(e)}\n")
# ==================== 主程序入口 ====================
def main():
"""主函数"""
print("\n正在初始化代码Agent...")
# 检查环境变量
required_env_vars = [
"LAZYLLM_DEEPSEEK_API_KEY",
"LAZYLLM_OPENAI_API_KEY",
"LAZYLLM_GLM_API_KEY",
"LAZYLLM_SENSENOVA_API_KEY",
"LAZYLLM_KIMI_API_KEY"
]
missing_vars = []
for var in required_env_vars:
if not os.environ.get(var):
missing_vars.append(var)
if missing_vars:
print("\n警告: 以下环境变量未设置,可能影响模型调用:")
for var in missing_vars:
print(f" - {var}")
print("\n请设置相应的API密钥以使用在线模型。\n")
# 启动交互式CLI
cli = InteractiveCLI()
cli.run()
if __name__ == "__main__":
main()
6.8 示例八:生成一个多智能体对话系统
prompt:
在文件./LazyLLM/example8.py中使用lazyllm实现一个多智能体对话系统,使不同角色在特定话题下进行层次分明且自然的互动。要求在系统中引入一个director来控制发言顺序与对话终止逻辑,其他dialogueagent作为受控角色参与讨论。director决定谁来发言,并判断是否结束对话。我可以在命令行给出讨论的话题,过程中系统输出各个智能体每轮讨论内容,最后输出给我结果。
"""
多智能体对话系统
- Director: 控制发言顺序和对话终止
- DialogueAgents: 不同角色的参与者
"""
import lazyllm
from lazyllm import loop, pipeline, parallel, bind
import sys
class DialogueAgent:
"""对话智能体基类"""
def __init__(self, name, role_description, llm):
self.name = name
self.role_description = role_description
self.llm = llm
self.history = []
def __call__(self, context):
"""参与对话"""
# 构建prompt,包含角色设定和上下文
prompt = f"""你是{self.name}。{self.role_description}
当前讨论话题的上下文:
{context}
请基于你的角色和以上上下文,发表你的观点(100字以内):"""
response = self.llm(prompt)
self.history.append({"role": "assistant", "content": response})
return f"{self.name}: {response}"
class Director:
"""导演智能体,控制对话流程"""
def __init__(self, llm, agents, max_rounds=5):
self.llm = llm
self.agents = agents
self.max_rounds = max_rounds
self.current_round = 0
self.conversation_history = []
def decide_next_speaker(self, topic, history_text):
"""决定下一个发言者"""
prompt = f"""你是对话导演,负责控制多智能体对话的流程。
讨论话题:{topic}
当前对话历史:
{history_text}
可用参与者:
{chr(10).join([f'- {agent.name}: {agent.role_description[:30]}...' for agent in self.agents])}
基于以上信息,请决定下一个应该发言的智能体。只需返回智能体名称,不要解释。
如果对话应该结束,请返回"END"。
决策:"""
decision = self.llm(prompt).strip()
return decision
def should_end_conversation(self, topic, history_text):
"""判断是否应该结束对话"""
prompt = f"""你是对话导演,负责判断讨论是否应该结束。
讨论话题:{topic}
当前对话历史:
{history_text}
请判断讨论是否已经充分、是否达成了共识或自然结束。
如果应该结束,返回"YES";如果应该继续,返回"NO"。
判断:"""
result = self.llm(prompt).strip().upper()
return "YES" in result
def generate_summary(self, topic, history_text):
"""生成对话总结"""
prompt = f"""请对以下讨论进行总结:
讨论话题:{topic}
对话记录:
{history_text}
请总结主要观点和结论:"""
return self.llm(prompt)
def create_multi_agent_system(topic):
"""创建多智能体对话系统"""
# 创建共享的LLM
llm = lazyllm.OnlineChatModule()
# 创建不同角色的对话智能体
agents = [
DialogueAgent(
name="技术专家",
role_description="你是一位技术专家,关注技术可行性、实现难度和创新性。你倾向于从技术角度分析问题。",
llm=llm
),
DialogueAgent(
name="产品经理",
role_description="你是一位产品经理,关注用户需求、市场价值和商业可行性。你倾向于从用户和商业角度分析问题。",
llm=llm
),
DialogueAgent(
name="风险顾问",
role_description="你是一位风险顾问,关注潜在风险、合规性和安全性。你倾向于从风险控制角度分析问题。",
llm=llm
),
]
# 创建导演智能体
director = Director(llm, agents, max_rounds=5)
# 初始化对话历史
conversation_history = [f"讨论话题:{topic}"]
print(f"\n{'='*60}")
print(f"开始讨论话题:{topic}")
print(f"{'='*60}\n")
# 第一轮:每个agent依次发言
round_num = 1
while round_num <= director.max_rounds:
print(f"\n{'='*60}")
print(f"第 {round_num} 轮讨论")
print(f"{'='*60}")
round_history = []
# 每个agent发言
for agent in agents:
context = "\n".join(conversation_history)
response = agent(context)
round_history.append(response)
conversation_history.append(response)
print(f"\n{response}")
# 导演判断是否结束
history_text = "\n".join(conversation_history)
if director.should_end_conversation(topic, history_text):
print(f"\n{'='*60}")
print("Director: 讨论已充分,准备结束")
print(f"{'='*60}")
break
round_num += 1
# 生成总结
print(f"\n{'='*60}")
print("最终总结")
print(f"{'='*60}\n")
summary = director.generate_summary(topic, "\n".join(conversation_history))
print(summary)
return summary
def main():
"""主函数"""
# 从命令行获取话题
if len(sys.argv) > 1:
topic = " ".join(sys.argv[1:])
else:
topic = input("请输入讨论话题:")
if not topic.strip():
print("错误:话题不能为空")
sys.exit(1)
# 运行多智能体对话系统
create_multi_agent_system(topic)
if __name__ == "__main__":
main()
6.9 示例九:生成格式转换Agent
prompt:
在./LazyLLM/example10.py中使用lazyllm实现一个格式转换agent,专门将word文档转为latex文档,并且保存在相同目录下。为了解决超长文件的问题,对文档进行切分,并使用rag进行存储,要求并行执行,最后一并拼接。转换完成后用户可以根据文件内容进行问询。执行文件后,用户从命令行输入文件路径,执行结束后用户可以从命令行进行问询。要求体现当前转换进度
"""
Word转LaTeX格式转换Agent
支持超长文档切分、并行转换、RAG存储和问答功能
"""
import os
import sys
import lazyllm
from lazyllm import bind, pipeline, parallel, warp
from lazyllm.tools import ReactAgent
from tqdm import tqdm
import tempfile
import shutil
# 设置API密钥(请根据实际情况配置)
# os.environ['LAZYLLM_API_KEY'] = 'your-api-key'
class WordToLatexConverter:
"""Word文档转LaTeX转换器"""
def __init__(self, chunk_size=2000, overlap=200):
"""
初始化转换器
Args:
chunk_size: 每个文档块的大小(字符数)
overlap: 文档块之间的重叠字符数
"""
self.chunk_size = chunk_size
self.overlap = overlap
self.documents = None
self.retriever = None
self.llm = None
self.converted_chunks = []
self.progress_bar = None
# 初始化LLM模型
self._init_llm()
def _init_llm(self):
"""初始化大语言模型"""
# 使用在线模型,支持多种模型源
try:
self.llm = lazyllm.OnlineChatModule(source='deepseek', model='deepseek-chat')
except:
# 如果deepseek不可用,尝试其他模型
try:
self.llm = lazyllm.OnlineChatModule()
except:
print("警告:无法初始化在线模型,请配置API密钥")
self.llm = None
def read_word_document(self, file_path):
"""
读取Word文档内容
Args:
file_path: Word文档路径
Returns:
str: 文档文本内容
"""
try:
# 使用python-docx读取Word文档
import docx
doc = docx.Document(file_path)
# 提取所有段落文本
full_text = []
for para in doc.paragraphs:
if para.text.strip():
full_text.append(para.text)
# 提取表格内容
for table in doc.tables:
for row in table.rows:
row_text = []
for cell in row.cells:
if cell.text.strip():
row_text.append(cell.text.strip())
if row_text:
full_text.append(' | '.join(row_text))
content = '\n\n'.join(full_text)
print(f"✓ 成功读取文档: {file_path}")
print(f" 文档总长度: {len(content)} 字符")
return content
except ImportError:
print("错误:请先安装python-docx库: pip install python-docx")
sys.exit(1)
except Exception as e:
print(f"错误:读取Word文档失败: {e}")
sys.exit(1)
def split_document(self, content):
"""
将文档切分成多个块
Args:
content: 文档内容
Returns:
list: 文档块列表
"""
chunks = []
start = 0
content_length = len(content)
while start < content_length:
# 计算当前块的结束位置
end = min(start + self.chunk_size, content_length)
# 如果不是最后一块,尝试在段落边界处切割
if end < content_length:
# 查找最近的段落结束符(换行符)
paragraph_end = content.rfind('\n\n', start, end)
if paragraph_end == -1:
paragraph_end = content.rfind('\n', start, end)
if paragraph_end != -1 and paragraph_end > start:
end = paragraph_end
# 提取当前块
chunk = content[start:end].strip()
if chunk:
chunks.append({
'index': len(chunks),
'content': chunk,
'start': start,
'end': end
})
# 移动起始位置(考虑重叠)
start = end - self.overlap if end < content_length else content_length
print(f"✓ 文档切分完成: 共 {len(chunks)} 个片段")
return chunks
def create_rag_storage(self, chunks, file_dir):
"""
创建RAG存储
Args:
chunks: 文档块列表
file_dir: 文件所在目录
"""
# 创建临时目录存储文档块
temp_dir = tempfile.mkdtemp(prefix='word_chunks_')
try:
# 将每个块保存为单独的文本文件
for chunk in chunks:
chunk_file = os.path.join(temp_dir, f"chunk_{chunk['index']:04d}.txt")
with open(chunk_file, 'w', encoding='utf-8') as f:
f.write(chunk['content'])
# 创建Document对象
self.documents = lazyllm.Document(
dataset_path=temp_dir,
embed=lazyllm.OnlineEmbeddingModule(),
manager=False
)
# 创建细粒度的节点组
self.documents.create_node_group(
name="chunks",
transform=lambda s: [s] # 每个文件作为一个节点
)
# 创建检索器
self.retriever = lazyllm.Retriever(
doc=self.documents,
group_name="chunks",
similarity="bm25_chinese",
topk=min(5, len(chunks))
)
print(f"✓ RAG存储创建完成")
except Exception as e:
print(f"警告:RAG存储创建失败: {e}")
self.documents = None
self.retriever = None
return temp_dir
def convert_chunk_to_latex(self, chunk_data):
"""
将单个文档块转换为LaTeX格式
Args:
chunk_data: 包含索引和内容的数据字典
Returns:
dict: 包含索引和LaTeX内容的结果
"""
index = chunk_data['index']
content = chunk_data['content']
# 构建转换提示词
prompt = f"""请将以下Word文档内容转换为LaTeX格式。
要求:
1. 保持原文的段落结构和层次
2. 将标题转换为适当的LaTeX章节命令(\\section, \\subsection等)
3. 将列表转换为itemize或enumerate环境
4. 保持表格结构(如果有)
5. 处理特殊字符,确保LaTeX兼容性
6. 只输出LaTeX代码,不要输出任何解释
原文内容:
{content}
LaTeX代码:"""
try:
if self.llm:
# 使用LLM进行转换
latex_content = self.llm(prompt)
else:
# 如果没有LLM,进行基础转换
latex_content = self._basic_convert_to_latex(content)
# 更新进度
if self.progress_bar:
self.progress_bar.update(1)
return {
'index': index,
'latex': latex_content,
'success': True
}
except Exception as e:
print(f"\n警告:片段 {index} 转换失败: {e}")
if self.progress_bar:
self.progress_bar.update(1)
return {
'index': index,
'latex': f"% 片段 {index} 转换失败\n% 原始内容: {content[:100]}...",
'success': False
}
def _basic_convert_to_latex(self, content):
"""
基础LaTeX转换(不使用LLM)
Args:
content: 文本内容
Returns:
str: LaTeX代码
"""
lines = content.split('\n')
latex_lines = []
in_list = False
list_type = None
for line in lines:
line = line.strip()
if not line:
if in_list:
latex_lines.append(f'\\end{{{list_type}}}')
in_list = False
list_type = None
latex_lines.append('')
continue
# 检测标题(简单的启发式规则)
if line.endswith(':') or line.endswith(':'):
if in_list:
latex_lines.append(f'\\end{{{list_type}}}')
in_list = False
latex_lines.append(f'\\subsection{{{line[:-1]}}}')
# 检测列表项
elif line.startswith(('•', '-', '*', '·')):
if not in_list or list_type != 'itemize':
if in_list:
latex_lines.append(f'\\end{{{list_type}}}')
latex_lines.append('\\begin{itemize}')
in_list = True
list_type = 'itemize'
item_text = line[1:].strip()
latex_lines.append(f' \\item {item_text}')
# 检测编号列表
elif line[0].isdigit() and line[1:3] in ['. ', '、', '.']:
if not in_list or list_type != 'enumerate':
if in_list:
latex_lines.append(f'\\end{{{list_type}}}')
latex_lines.append('\\begin{enumerate}')
in_list = True
list_type = 'enumerate'
item_text = line[3:].strip() if line[1] == '.' else line[2:].strip()
latex_lines.append(f' \\item {item_text}')
else:
if in_list:
latex_lines.append(f'\\end{{{list_type}}}')
in_list = False
list_type = None
# 转义特殊字符
line = self._escape_latex(line)
latex_lines.append(line)
if in_list:
latex_lines.append(f'\\end{{{list_type}}}')
return '\n'.join(latex_lines)
def _escape_latex(self, text):
"""转义LaTeX特殊字符"""
special_chars = {
'\\': '\\textbackslash{}',
'{': '\\{',
'}': '\\}',
'$': '\\$',
'&': '\\&',
'#': '\\#',
'^': '\\textasciicircum{}',
'_': '\\_',
'~': '\\textasciitilde{}',
'%': '\\%',
}
for char, replacement in special_chars.items():
text = text.replace(char, replacement)
return text
def parallel_convert(self, chunks):
"""
并行转换所有文档块
Args:
chunks: 文档块列表
Returns:
list: 转换后的LaTeX块列表
"""
print(f"\n开始并行转换 {len(chunks)} 个文档片段...")
# 创建进度条
self.progress_bar = tqdm(total=len(chunks), desc="转换进度", unit="片段")
# 使用Warp进行并行转换
with warp() as converter:
converter.convert = self.convert_chunk_to_latex
# 执行并行转换
results = converter(chunks)
# 关闭进度条
self.progress_bar.close()
self.progress_bar = None
# 按索引排序结果
sorted_results = sorted(results, key=lambda x: x['index'])
# 统计成功数量
success_count = sum(1 for r in sorted_results if r['success'])
print(f"✓ 转换完成: {success_count}/{len(chunks)} 个片段成功")
return sorted_results
def merge_latex(self, results, title="Converted Document"):
"""
合并所有LaTeX片段
Args:
results: 转换后的结果列表
title: 文档标题
Returns:
str: 完整的LaTeX文档
"""
# 构建LaTeX文档头部
header = r"""\documentclass[12pt,a4paper]{article}
\usepackage[UTF8]{ctex}
\usepackage{geometry}
\usepackage{hyperref}
\usepackage{listings}
\usepackage{xcolor}
\geometry{margin=2.5cm}
\title{""" + title + r"""}
\date{\today}
\begin{document}
\maketitle
"""
# 合并所有片段
body_parts = []
for result in results:
latex_content = result['latex']
body_parts.append(latex_content)
body_parts.append('\n\n% --- 片段分隔线 ---\n\n')
# 文档尾部
footer = r"""
\end{document}
"""
full_latex = header + '\n'.join(body_parts) + footer
return full_latex
def save_latex(self, latex_content, output_path):
"""
保存LaTeX文件
Args:
latex_content: LaTeX内容
output_path: 输出文件路径
"""
try:
with open(output_path, 'w', encoding='utf-8') as f:
f.write(latex_content)
print(f"✓ LaTeX文件已保存: {output_path}")
except Exception as e:
print(f"错误:保存文件失败: {e}")
sys.exit(1)
def convert(self, file_path):
"""
执行完整的转换流程
Args:
file_path: Word文档路径
Returns:
str: 输出的LaTeX文件路径
"""
print(f"\n{'='*60}")
print(f"Word转LaTeX转换器")
print(f"{'='*60}\n")
# 检查文件
if not os.path.exists(file_path):
print(f"错误:文件不存在: {file_path}")
sys.exit(1)
if not file_path.endswith(('.docx', '.doc')):
print(f"错误:不支持的文件格式,请使用.docx或.doc文件")
sys.exit(1)
# 获取文件信息
file_dir = os.path.dirname(os.path.abspath(file_path))
file_name = os.path.splitext(os.path.basename(file_path))[0]
output_path = os.path.join(file_dir, f"{file_name}.tex")
print(f"输入文件: {file_path}")
print(f"输出文件: {output_path}\n")
# 步骤1: 读取Word文档
print("步骤 1/5: 读取Word文档...")
content = self.read_word_document(file_path)
# 步骤2: 切分文档
print("\n步骤 2/5: 切分文档...")
chunks = self.split_document(content)
# 步骤3: 创建RAG存储
print("\n步骤 3/5: 创建RAG存储...")
temp_dir = self.create_rag_storage(chunks, file_dir)
# 步骤4: 并行转换
print("\n步骤 4/5: 并行转换为LaTeX...")
results = self.parallel_convert(chunks)
self.converted_chunks = results
# 步骤5: 合并并保存
print("\n步骤 5/5: 合并并保存LaTeX文件...")
latex_content = self.merge_latex(results, title=file_name)
self.save_latex(latex_content, output_path)
# 清理临时目录
if temp_dir and os.path.exists(temp_dir):
shutil.rmtree(temp_dir)
print(f"\n{'='*60}")
print(f"转换完成!")
print(f"{'='*60}\n")
return output_path
def answer_question(self, question):
"""
基于转换后的文档内容回答问题
Args:
question: 用户问题
Returns:
str: 回答内容
"""
if not self.converted_chunks:
return "错误:还没有转换任何文档,请先执行转换操作。"
print(f"\n正在检索相关内容...")
# 如果有RAG检索器,使用RAG检索
if self.retriever:
try:
doc_nodes = self.retriever(query=question)
context = "".join([node.get_content() for node in doc_nodes])
except:
# 如果RAG检索失败,使用简单的关键词匹配
context = self._simple_search(question)
else:
# 使用简单的关键词匹配
context = self._simple_search(question)
# 构建问答提示词
prompt = f"""基于以下文档内容回答问题。
文档内容:
{context}
问题:{question}
请根据文档内容提供准确、简洁的回答。如果文档中没有相关信息,请明确说明。"""
try:
if self.llm:
answer = self.llm(prompt)
return answer
else:
return "错误:LLM模型未初始化,无法回答问题。"
except Exception as e:
return f"错误:回答问题失败: {e}"
def _simple_search(self, question):
"""
简单的关键词搜索
Args:
question: 问题
Returns:
str: 相关内容
"""
# 提取关键词(简单实现:取问题中的前5个词)
keywords = question.split()[:5]
matched_contents = []
for chunk in self.converted_chunks:
content = chunk.get('latex', '')
# 检查是否包含关键词
score = sum(1 for kw in keywords if kw in content)
if score > 0:
matched_contents.append((score, content))
# 按匹配度排序
matched_contents.sort(key=lambda x: x[0], reverse=True)
# 返回前3个最相关的内容
top_contents = [content for _, content in matched_contents[:3]]
return '\n\n'.join(top_contents) if top_contents else "未找到相关内容"
def main():
"""主函数"""
print("\n" + "="*60)
print("Word转LaTeX格式转换Agent")
print("="*60)
print("\n功能说明:")
print("1. 将Word文档(.docx/.doc)转换为LaTeX格式")
print("2. 支持超长文档切分和并行转换")
print("3. 使用RAG技术存储文档内容")
print("4. 转换后支持基于文档内容的问答")
print("\n" + "="*60 + "\n")
# 创建转换器实例
converter = WordToLatexConverter(chunk_size=2000, overlap=200)
# 获取文件路径
while True:
file_path = input("请输入Word文档路径 (或输入'quit'退出): ").strip()
if file_path.lower() == 'quit':
print("\n感谢使用,再见!")
sys.exit(0)
if not file_path:
print("错误:请输入有效的文件路径")
continue
# 执行转换
try:
output_path = converter.convert(file_path)
break
except Exception as e:
print(f"\n转换失败: {e}")
retry = input("是否重试? (y/n): ").strip().lower()
if retry != 'y':
sys.exit(1)
# 问答循环
print("\n" + "="*60)
print("转换完成!现在您可以基于文档内容进行问答")
print("提示:输入'quit'退出问答模式")
print("="*60 + "\n")
while True:
question = input("问题: ").strip()
if question.lower() == 'quit':
print("\n感谢使用,再见!")
break
if not question:
continue
# 回答问题
answer = converter.answer_question(question)
print(f"\n回答: {answer}\n")
if __name__ == '__main__':
main()
6.10 示例十:生成基于LazyLLM的智能助手
prompt:
在文件./LazyLLM/example10.py中使用lazyllm实现一个热点分析agent,要求使用lazyllm的搜索工具,并且可以实现对当前用户关心的热点内容进行筛选和分析,过滤掉不相关甚至虚假的内容,如果觉得内容不够充分可以进行多轮搜索和分析,最后给出markdown报告并保存在本地。用户从命令行输入关心的热点
"""
热点分析Agent
使用LazyLLM实现的热点内容筛选和分析Agent
支持多轮搜索、内容筛选、真实性验证和Markdown报告生成
"""
import os
import sys
import json
import re
from datetime import datetime
from typing import List, Dict, Any
import lazyllm
from lazyllm.tools import ReactAgent, fc_register
from lazyllm.tools.tools import GoogleSearch
# ==================== 全局配置 ====================
# 搜索API配置(请根据实际情况配置)
# AIzaSyB4uJIll7SdEV_3Qn9P4um35c5bXh1RGkE
# b440acebc11254cb0
GOOGLE_API_KEY = os.environ.get('GOOGLE_API_KEY', '')
GOOGLE_CX = os.environ.get('GOOGLE_CX', '')
# 存储搜索结果和分析数据的全局变量
_search_results_cache = []
_analysis_results = []
_current_topic = ""
# ==================== 工具函数 ====================
@fc_register('tool')
def search_hot_topics(topic: str, max_results: int = 10) -> str:
"""
搜索与指定热点话题相关的最新内容。
Args:
topic (str): 热点话题关键词
max_results (int): 返回的最大结果数量,默认10条
Returns:
str: 搜索结果的JSON格式字符串
"""
global _search_results_cache, _current_topic
try:
# 使用Google搜索(需要配置API密钥)
# 如果未配置,使用模拟数据演示
if 'GOOGLE_API_KEY' in globals() and GOOGLE_API_KEY:
searcher = GoogleSearch(
custom_search_api_key=GOOGLE_API_KEY,
search_engine_id=GOOGLE_CX
)
results = searcher(query=topic)
else:
# 模拟搜索结果(实际使用时请配置Google API)
results = _simulate_search(topic)
# 缓存搜索结果
_search_results_cache.extend(results)
_current_topic = topic
# 格式化搜索结果
formatted_results = []
for idx, item in enumerate(results, 1):
formatted_results.append({
'id': idx,
'title': item.get('title', '无标题'),
'link': item.get('link', ''),
'snippet': item.get('snippet', ''),
'source': item.get('source', '未知来源'),
'timestamp': item.get('timestamp', datetime.now().isoformat())
})
return json.dumps(formatted_results, ensure_ascii=False, indent=2)
except Exception as e:
return f"搜索失败: {str(e)}"
def _simulate_search(topic: str, max_results: int) -> List[Dict]:
"""
模拟搜索结果的辅助函数(用于演示)
"""
# 生成模拟搜索结果
simulated_results = []
sources = ['新闻网站', '社交媒体', '论坛', '博客', '视频平台']
for i in range(min(max_results, 10)):
simulated_results.append({
'title': f'{topic} - 相关内容 {i+1}',
'link': f'https://example.com/article/{i+1}',
'snippet': f'这是关于{topic}的第{i+1}条搜索结果摘要。包含了该话题的关键信息和讨论要点...',
'source': sources[i % len(sources)],
'timestamp': datetime.now().isoformat()
})
return simulated_results
@fc_register('tool')
def filter_relevant_content(topic: str, content_list: str) -> str:
"""
筛选与热点话题高度相关的内容,过滤掉不相关或偏离主题的信息。
Args:
topic (str): 热点话题关键词
content_list (str): JSON格式的内容列表字符串
Returns:
str: 筛选后的相关内容JSON格式字符串
"""
try:
contents = json.loads(content_list)
relevant_items = []
# 定义相关性关键词(基于主题扩展)
topic_keywords = topic.lower().split()
for item in contents:
title = item.get('title', '').lower()
snippet = item.get('snippet', '').lower()
# 计算相关性得分
relevance_score = 0
for keyword in topic_keywords:
if keyword in title:
relevance_score += 3
if keyword in snippet:
relevance_score += 1
# 设置相关性阈值
if relevance_score >= 2:
item['relevance_score'] = relevance_score
item['is_relevant'] = True
relevant_items.append(item)
else:
item['is_relevant'] = False
item['relevance_score'] = relevance_score
# 按相关性得分排序
relevant_items.sort(key=lambda x: x['relevance_score'], reverse=True)
return json.dumps({
'filtered_count': len(relevant_items),
'total_count': len(contents),
'relevant_items': relevant_items[:10] # 返回前10条最相关的
}, ensure_ascii=False, indent=2)
except Exception as e:
return f"内容筛选失败: {str(e)}"
@fc_register('tool')
def verify_content_authenticity(content_list: str) -> str:
"""
验证内容的真实性和可信度,识别可能的虚假信息。
Args:
content_list (str): JSON格式的内容列表字符串
Returns:
str: 验证后的内容JSON格式字符串,包含可信度评分
"""
try:
contents = json.loads(content_list)
verified_items = []
# 可信度评估标准
high_credibility_sources = ['官方媒体', '政府网站', '知名新闻机构', '权威博客']
low_credibility_indicators = ['谣言', '虚假', '骗局', '不实', '伪造']
for item in contents.get('relevant_items', []):
credibility_score = 5 # 基础可信度分数(满分10分)
# 根据来源评估
source = item.get('source', '未知')
if any(high in source for high in high_credibility_sources):
credibility_score += 3
elif source in ['社交媒体', '论坛']:
credibility_score -= 1
# 检查内容中的可疑关键词
content_text = f"{item.get('title', '')} {item.get('snippet', '')}".lower()
for indicator in low_credibility_indicators:
if indicator in content_text:
credibility_score -= 2
# 确保分数在合理范围内
credibility_score = max(1, min(10, credibility_score))
item['credibility_score'] = credibility_score
item['is_credible'] = credibility_score >= 6
verified_items.append(item)
# 分离高可信度和低可信度内容
high_credibility = [item for item in verified_items if item.get('is_credible', False)]
low_credibility = [item for item in verified_items if not item.get('is_credible', False)]
return json.dumps({
'high_credibility_count': len(high_credibility),
'low_credibility_count': len(low_credibility),
'high_credibility_items': high_credibility,
'low_credibility_items': low_credibility
}, ensure_ascii=False, indent=2)
except Exception as e:
return f"真实性验证失败: {str(e)}"
@fc_register('tool')
def analyze_content_trends(content_list: str) -> str:
"""
分析热点内容的趋势、关键观点和发展态势。
Args:
content_list (str): JSON格式的内容列表字符串
Returns:
str: 趋势分析结果的JSON格式字符串
"""
try:
contents = json.loads(content_list)
items = contents.get('high_credibility_items', [])
if not items:
return json.dumps({'error': '没有足够的内容进行分析'}, ensure_ascii=False)
# 提取关键观点(基于内容摘要)
key_points = []
sentiment_indicators = {
'positive': ['支持', '赞同', '积极', '利好', '成功', '突破'],
'negative': ['反对', '批评', '消极', '问题', '风险', '危机'],
'neutral': ['报道', '分析', '指出', '表示', '认为']
}
sentiment_count = {'positive': 0, 'negative': 0, 'neutral': 0}
for item in items:
snippet = item.get('snippet', '')
title = item.get('title', '')
# 提取关键句子作为观点
sentences = re.split(r'[。!?]', snippet)
for sent in sentences[:2]: # 取前2句
if len(sent) > 10:
key_points.append(sent.strip())
# 情感分析
text = (title + snippet).lower()
for sentiment, keywords in sentiment_indicators.items():
for keyword in keywords:
if keyword in text:
sentiment_count[sentiment] += 1
break
# 确定整体情感倾向
total = sum(sentiment_count.values())
if total > 0:
sentiment_distribution = {
k: round(v/total*100, 1) for k, v in sentiment_count.items()
}
dominant_sentiment = max(sentiment_count.items(), key=lambda x: x[1])[0]
else:
sentiment_distribution = {'positive': 0, 'negative': 0, 'neutral': 100}
dominant_sentiment = 'neutral'
# 统计来源分布
source_distribution = {}
for item in items:
source = item.get('source', '未知')
source_distribution[source] = source_distribution.get(source, 0) + 1
analysis_result = {
'total_analyzed': len(items),
'key_points': list(set(key_points))[:10], # 去重并限制数量
'sentiment_analysis': {
'dominant_sentiment': dominant_sentiment,
'distribution': sentiment_distribution
},
'source_distribution': source_distribution,
'avg_credibility': round(
sum(item.get('credibility_score', 5) for item in items) / len(items), 1
) if items else 0
}
return json.dumps(analysis_result, ensure_ascii=False, indent=2)
except Exception as e:
return f"趋势分析失败: {str(e)}"
@fc_register('tool')
def check_need_more_search(analysis_result: str) -> str:
"""
检查是否需要进一步搜索以获取更充分的信息。
Args:
analysis_result (str): 当前分析结果的JSON格式字符串
Returns:
str: JSON格式字符串,包含是否需要更多搜索的判断和建议
"""
try:
analysis = json.loads(analysis_result)
total_analyzed = analysis.get('total_analyzed', 0)
key_points = analysis.get('key_points', [])
avg_credibility = analysis.get('avg_credibility', 0)
# 判断是否需要更多搜索
need_more_search = False
reasons = []
suggested_queries = []
if total_analyzed < 5:
need_more_search = True
reasons.append("分析的内容数量较少,需要获取更多来源")
suggested_queries.append(f"{_current_topic} 最新消息")
if len(key_points) < 3:
need_more_search = True
reasons.append("关键观点不足,需要深入挖掘")
suggested_queries.append(f"{_current_topic} 深度分析")
if avg_credibility < 7:
need_more_search = True
reasons.append("整体可信度较低,需要寻找更权威来源")
suggested_queries.append(f"{_current_topic} 官方发布")
result = {
'need_more_search': need_more_search,
'reasons': reasons,
'suggested_queries': suggested_queries,
'current_stats': {
'total_analyzed': total_analyzed,
'key_points_count': len(key_points),
'avg_credibility': avg_credibility
}
}
return json.dumps(result, ensure_ascii=False, indent=2)
except Exception as e:
return f"检查失败: {str(e)}"
@fc_register('tool')
def generate_markdown_report(topic: str, analysis_data: str, output_path: str) -> str:
"""
生成热点分析的Markdown格式报告并保存到本地。
Args:
topic (str): 热点话题
analysis_data (str): 分析数据的JSON格式字符串
output_path (str): 报告保存路径
Returns:
str: 保存结果信息
"""
try:
data = json.loads(analysis_data)
# 构建Markdown报告
report = f"""# 热点分析报告:{topic}
**生成时间**: {datetime.now().strftime('%Y年%m月%d日 %H:%M:%S')}
**分析来源**: 多源信息聚合分析
---
## 📊 执行摘要
### 整体评估
- **分析内容数量**: {data.get('total_analyzed', 0)} 条
- **平均可信度**: {data.get('avg_credibility', 0)}/10
- **主导情感倾向**: {data.get('sentiment_analysis', {}).get('dominant_sentiment', 'neutral')}
### 情感分布
"""
# 添加情感分布
sentiment_dist = data.get('sentiment_analysis', {}).get('distribution', {})
for sentiment, percentage in sentiment_dist.items():
emoji = {'positive': '😊', 'negative': '😟', 'neutral': '😐'}.get(sentiment, '➖')
report += f"- {emoji} **{sentiment}**: {percentage}%\n"
# 添加关键观点
report += f"""
## 💡 关键观点
"""
key_points = data.get('key_points', [])
if key_points:
for idx, point in enumerate(key_points, 1):
report += f"{idx}. {point}\n\n"
else:
report += "暂无明确的关键观点提取。\n\n"
# 添加来源分布
report += """## 📰 信息来源分布
"""
source_dist = data.get('source_distribution', {})
if source_dist:
for source, count in sorted(source_dist.items(), key=lambda x: x[1], reverse=True):
report += f"- **{source}**: {count} 条\n"
else:
report += "暂无来源分布数据。\n"
# 添加可信度分析
report += f"""
## ✅ 可信度评估
- **整体可信度评分**: {data.get('avg_credibility', 0)}/10
- **评估标准**:
- 8-10分: 高度可信,来源权威
- 6-7分: 较为可信,需要交叉验证
- 4-5分: 可信度一般,需谨慎对待
- 1-3分: 可信度低,建议寻找更权威来源
## 📝 分析结论
基于对 {data.get('total_analyzed', 0)} 条相关信息的分析,关于 **{topic}** 的热点内容:
1. **内容质量**: 平均可信度为 {data.get('avg_credibility', 0)}/10
2. **舆论倾向**: 整体呈现 {data.get('sentiment_analysis', {}).get('dominant_sentiment', 'neutral')} 倾向
3. **信息来源**: 主要来自 {', '.join(list(source_dist.keys())[:3]) if source_dist else '多个渠道'}
## ⚠️ 免责声明
本报告基于公开信息自动分析生成,仅供参考:
- 分析结果不代表任何官方立场
- 建议结合更多权威来源进行交叉验证
- 对于重要决策,请咨询专业人士
---
*报告由 LazyLLM 热点分析Agent自动生成*
"""
# 保存报告
with open(output_path, 'w', encoding='utf-8') as f:
f.write(report)
return f"报告已成功保存到: {output_path}"
except Exception as e:
return f"报告生成失败: {str(e)}"
@fc_register('tool')
def get_report_path(topic: str) -> str:
"""
根据热点话题生成报告保存路径。
Args:
topic (str): 热点话题
Returns:
str: 报告文件路径
"""
# 清理话题中的特殊字符
clean_topic = re.sub(r'[^\w\s-]', '', topic).strip().replace(' ', '_')
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"热点分析_{clean_topic}_{timestamp}.md"
# 使用当前目录
return os.path.join(os.getcwd(), filename)
# ==================== Agent创建 ====================
def create_hotspot_analysis_agent():
"""
创建热点分析Agent
"""
# 使用在线模型
try:
llm = lazyllm.OnlineChatModule(
source='deepseek',
model='deepseek-chat',
stream=False
)
except:
# 如果deepseek不可用,尝试默认模型
try:
llm = lazyllm.OnlineChatModule()
except:
print("警告: 无法初始化在线模型,请配置API密钥")
return None
# 设置系统提示词
instruction = """你是一个专业的新闻热点分析助手,负责帮助用户筛选和分析热点内容。
你的核心职责:
1. **多轮搜索**: 根据用户关心的热点话题进行多轮搜索,确保信息充分
2. **内容筛选**: 从搜索结果中筛选出与话题高度相关的内容
3. **真实性验证**: 评估内容的可信度,过滤虚假和不实信息
4. **深度分析**: 分析热点趋势、关键观点、情感倾向和来源分布
5. **报告生成**: 生成结构化的Markdown分析报告
工作流程:
1. 接收用户输入的热点话题
2. 执行第一轮搜索获取相关信息
3. 筛选相关内容并验证真实性
4. 进行趋势分析
5. 评估是否需要更多搜索
6. 如需更多搜索,执行补充搜索并重新分析
7. 生成最终的Markdown报告并保存
注意事项:
- 优先选择高可信度的信息源(官方媒体、权威网站)
- 对社交媒体和论坛内容保持谨慎态度
- 确保报告客观、中立,避免主观偏见
- 明确标注不确定或需要验证的信息"""
llm.prompt(lazyllm.ChatPrompter(instruction=instruction))
# 创建ReactAgent,使用所有工具
tools = [
'search_hot_topics',
'filter_relevant_content',
'verify_content_authenticity',
'analyze_content_trends',
'check_need_more_search',
'generate_markdown_report',
'get_report_path'
]
agent = ReactAgent(
llm,
tools=tools,
max_retries=5,
return_trace=True
)
return agent
# ==================== 主函数 ====================
def analyze_hotspot(topic: str, agent: ReactAgent) -> tuple:
"""
执行热点分析的完整流程
Args:
topic (str): 热点话题
agent (ReactAgent): 分析Agent
Returns:
tuple: (分析结果, 报告路径)
"""
print(f"\n{'='*60}")
print(f"开始分析热点: {topic}")
print(f"{'='*60}\n")
# 获取报告保存路径
report_path = get_report_path(topic)
# 构建任务指令
task = f"""请对热点话题 "{topic}" 进行全面分析,并生成报告。
请按以下步骤执行:
**步骤1: 初始搜索**
使用 search_hot_topics 工具搜索 "{topic}" 的相关内容,获取10条结果。
**步骤2: 内容筛选**
使用 filter_relevant_content 工具筛选与话题相关的内容。
**步骤3: 真实性验证**
使用 verify_content_authenticity 工具验证筛选后内容的真实性。
**步骤4: 趋势分析**
使用 analyze_content_trends 工具分析内容的趋势和关键观点。
**步骤5: 评估是否需要更多搜索**
使用 check_need_more_search 工具判断是否需要进一步搜索。
**步骤6: 多轮搜索(如需要)**
如果步骤5判断需要更多搜索,请:
- 根据建议的查询词执行补充搜索
- 重新执行筛选、验证和分析步骤
- 合并所有分析结果
**步骤7: 生成报告**
使用 generate_markdown_report 工具生成Markdown报告,保存到: {report_path}
**要求:**
1. 确保获取充分的信息(至少5条高可信度内容)
2. 严格过滤不相关和虚假内容
3. 分析要全面,包括情感倾向、来源分布等
4. 报告要结构清晰、内容详实
5. 最终返回报告保存路径和分析摘要"""
print("正在执行分析,请稍候...\n")
# 执行分析
result = agent(task)
print(f"\n{'='*60}")
print("分析完成!")
print(f"{'='*60}\n")
return result, report_path
def main():
"""
主函数:处理命令行输入并执行热点分析
"""
print("\n" + "="*60)
print("热点分析Agent")
print("="*60)
print("\n功能说明:")
print("1. 分析用户关心的热点话题")
print("2. 多轮搜索获取相关信息")
print("3. 智能筛选和真实性验证")
print("4. 深度分析趋势和观点")
print("5. 生成Markdown格式分析报告")
print("\n提示: 输入 'quit' 退出程序")
print("="*60 + "\n")
# 创建Agent
agent = create_hotspot_analysis_agent()
if not agent:
print("错误: 无法创建分析Agent,请检查模型配置")
sys.exit(1)
while True:
# 获取用户输入
topic = input("请输入您关心的热点话题: ").strip()
# 检查退出命令
if topic.lower() == 'quit':
print("\n感谢使用,再见!")
break
# 检查空输入
if not topic:
print("错误: 请输入有效的话题\n")
continue
# 执行分析
try:
result, report_path = analyze_hotspot(topic, agent)
# 显示结果
print("分析结果:")
print("-" * 60)
print(result)
print("-" * 60)
print(f"\n📄 详细报告已保存至: {report_path}")
print("\n" + "="*60 + "\n")
except Exception as e:
print(f"\n错误: 分析过程中出现错误: {e}")
print("请检查网络连接和API配置,然后重试。\n")
if __name__ == '__main__':
main()
6.11 示例十一:编写微调推理脚本
prompt:
"""
LazyLLM 从数据加载到微调推理一键完成示例
本脚本演示如何使用 LazyLLM 实现完整的大模型微调流程:
1. 数据准备 - 准备训练数据
2. 模型微调 - 使用 LLaMA-Factory 进行 LoRA 微调
3. 模型部署 - 自动部署微调后的模型
4. 推理测试 - 使用微调后的模型进行推理
作者: LazyLLM Team
日期: 2026-02-03
"""
import os
import json
import platform
import lazyllm
from lazyllm import finetune, deploy, launchers
# ============================================
# 配置参数
# ============================================
# 模型配置
BASE_MODEL = "qwen2-1.5b" # 基础模型,可以是 HuggingFace 模型名或本地路径
TARGET_PATH = "./output/finetuned_model" # 微调后模型保存路径
# 数据配置
TRAIN_DATA_PATH = "./data/train.json" # 训练数据路径
EVAL_DATA_PATH = "./data/eval.json" # 评测数据路径(可选)
DATASET_DIR = "./data" # 数据集目录
# 微调配置
LEARNING_RATE = 1e-4 # 学习率
NUM_EPOCHS = 3.0 # 训练轮数
BATCH_SIZE = 1 # 每设备批次大小
GRADIENT_ACCUMULATION = 8 # 梯度累积步数
CUTOFF_LEN = 2048 # 最大序列长度
LORA_R = 8 # LoRA 秩
LORA_ALPHA = 32 # LoRA alpha
SAVE_STEPS = 100 # 每多少步保存一次
EVAL_STEPS = 50 # 每多少步评估一次
# 检测系统环境
IS_MAC = platform.system() == "Darwin"
HAS_GPU = os.system("nvidia-smi > /dev/null 2>&1") == 0 if not IS_MAC else False
# ============================================
# 步骤 1: 准备示例数据
# ============================================
def prepare_sample_data():
"""
创建示例训练数据,用于演示微调流程
数据格式遵循 Alpaca 格式:instruction, input, output
"""
# 创建数据目录
os.makedirs(DATASET_DIR, exist_ok=True)
# 示例训练数据:技术问答对
train_data = [
{
"instruction": "解释什么是机器学习",
"input": "",
"output": "机器学习是一种人工智能方法,通过数据和算法让计算机自动学习和改进,而无需显式编程。"
},
{
"instruction": "描述深度学习的基本原理",
"input": "",
"output": "深度学习基于人工神经网络,通过多层非线性变换学习数据的层次化特征表示。"
},
{
"instruction": "什么是Transformer架构",
"input": "",
"output": "Transformer是一种基于自注意力机制的神经网络架构,用于处理序列数据,广泛应用于NLP任务。"
},
{
"instruction": "解释LoRA微调方法",
"input": "",
"output": "LoRA(Low-Rank Adaptation)是一种参数高效微调方法,通过低秩矩阵来微调预训练模型,显著减少训练参数。"
},
{
"instruction": "什么是自然语言处理",
"input": "",
"output": "自然语言处理(NLP)是人工智能的一个分支,专注于计算机与人类语言之间的交互和理解。"
},
{
"instruction": "解释神经网络中的反向传播算法",
"input": "",
"output": "反向传播是一种训练神经网络的算法,通过计算损失函数对参数的梯度,从输出层向输入层逐层更新权重。"
},
{
"instruction": "什么是注意力机制",
"input": "",
"output": "注意力机制允许模型在处理输入时动态地关注不同部分,为重要特征分配更高的权重。"
},
{
"instruction": "描述预训练语言模型的优势",
"input": "",
"output": "预训练语言模型通过在大规模语料上预训练,可以学习丰富的语言表示,并在下游任务中快速适应。"
}
]
# 示例评测数据
eval_data = [
{
"instruction": "解释强化学习的基本概念",
"input": "",
"output": "强化学习是一种机器学习方法,智能体通过与环境交互,根据奖励信号学习最优行为策略。"
},
{
"instruction": "什么是计算机视觉",
"input": "",
"output": "计算机视觉是让计算机理解和分析视觉信息的技术,包括图像识别、目标检测等任务。"
}
]
# 保存训练数据
with open(TRAIN_DATA_PATH, 'w', encoding='utf-8') as f:
json.dump(train_data, f, ensure_ascii=False, indent=2)
# 保存评测数据
with open(EVAL_DATA_PATH, 'w', encoding='utf-8') as f:
json.dump(eval_data, f, ensure_ascii=False, indent=2)
# 创建 dataset_info.json(LLaMA-Factory 需要)
dataset_info = {
"tech_qa": {
"file_name": "train.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
}
}
with open(os.path.join(DATASET_DIR, "dataset_info.json"), 'w', encoding='utf-8') as f:
json.dump(dataset_info, f, ensure_ascii=False, indent=2)
print(f"✓ 数据准备完成")
print(f" - 训练数据: {TRAIN_DATA_PATH} ({len(train_data)} 条)")
print(f" - 评测数据: {EVAL_DATA_PATH} ({len(eval_data)} 条)")
print(f" - 数据集信息: {os.path.join(DATASET_DIR, 'dataset_info.json')}")
return train_data, eval_data
# ============================================
# 步骤 2: 配置并执行微调
# ============================================
def setup_finetune_model():
"""
配置微调模型
使用 TrainableModule 统一接口管理微调和部署
"""
print("\n" + "="*50)
print("配置微调模型")
print("="*50)
# 方式 1: 使用 AutoFinetune(自动选择微调方法)
# model = lazyllm.TrainableModule(BASE_MODEL, target_path=TARGET_PATH) \
# .finetune_method(finetune.auto) \
# .trainset(TRAIN_DATA_PATH) \
# .mode('finetune')
# 方式 2: 使用 LLaMA-Factory 进行微调(推荐)
model = lazyllm.TrainableModule(BASE_MODEL, target_path=TARGET_PATH) \
.mode('finetune') \
.trainset(TRAIN_DATA_PATH) \
.finetune_method((
finetune.llamafactory,
{
# 基础训练参数
'learning_rate': LEARNING_RATE,
'num_train_epochs': NUM_EPOCHS,
'per_device_train_batch_size': BATCH_SIZE,
'gradient_accumulation_steps': GRADIENT_ACCUMULATION,
'cutoff_len': CUTOFF_LEN,
'lora_r': LORA_R,
'lora_alpha': LORA_ALPHA,
'save_steps': SAVE_STEPS,
'eval_steps': EVAL_STEPS,
'val_size': 0.1, # 10% 数据用于验证
# 模板和数据集配置
'template': 'alpaca', # 使用 Alpaca 模板
'dataset_dir': DATASET_DIR,
'dataset': 'tech_qa', # 数据集名称
# 优化配置
'warmup_ratio': 0.1,
'lr_scheduler_type': 'cosine',
'fp16': True,
# 日志配置
'logging_steps': 10,
'plot_loss': True,
'overwrite_output_dir': True,
# 启动器配置(根据实际环境调整)
# 'launcher': launchers.remote(ngpus=1), # 远程集群
# 'launcher': launchers.sco(ngpus=1), # SCO 平台
}
))
# 设置评测数据集(可选)
# model.evalset(EVAL_DATA_PATH)
print(f"✓ 微调配置完成")
print(f" - 基础模型: {BASE_MODEL}")
print(f" - 目标路径: {TARGET_PATH}")
print(f" - 训练数据: {TRAIN_DATA_PATH}")
print(f" - 学习率: {LEARNING_RATE}")
print(f" - 训练轮数: {NUM_EPOCHS}")
print(f" - LoRA 秩: {LORA_R}")
return model
# ============================================
# 步骤 3: 配置模型部署
# ============================================
def setup_deploy_model(model):
"""
配置模型部署方法
根据系统环境选择合适的部署方式
"""
print("\n" + "="*50)
print("配置模型部署")
print("="*50)
transformers_available = False
try:
from lazyllm.thirdparty import transformers
transformers_available = True
except ImportError:
pass
if IS_MAC or not HAS_GPU:
if transformers_available:
print("检测到 Mac/Apple Silicon 或 CPU 环境,将使用 transformers 库进行推理")
print(" - 注意:微调完成后将直接使用 transformers 加载模型进行推理")
model._use_transformers_directly = True
model.deploy_method(deploy.dummy)
else:
print("错误: transformers 库未安装,需要安装以下依赖:")
print(" pip install transformers torch peft accelerate")
raise ImportError("transformers 库未安装")
elif HAS_GPU:
print("检测到 NVIDIA GPU,使用 VLLM 部署")
model._use_transformers_directly = False
model.deploy_method(deploy.vllm)
print(f"✓ 部署配置完成")
return model
def run_finetune_and_deploy(model):
"""
只执行微调,跳过部署
推理将使用 transformers 直接进行
"""
print("\n" + "="*50)
print("开始执行微调流程")
print("="*50)
print("流程: 数据加载 -> 模型微调\n")
try:
print("开始微调(这可能需要一些时间)...")
model.update()
import os
finetuned_path = None
target_merge = os.path.join(TARGET_PATH, 'lazyllm_merge')
if os.path.exists(target_merge):
for root, dirs, files in os.walk(target_merge):
for f in files:
if f.endswith(('.bin', '.safetensors', '.pt')):
finetuned_path = root
break
if finetuned_path:
break
if finetuned_path:
model._finetuned_model_path = finetuned_path
else:
model._finetuned_model_path = BASE_MODEL
print("\n" + "="*50)
print("✓ 微调完成!")
print("="*50)
print(f"模型已保存至: {model._finetuned_model_path}")
return True
except Exception as e:
print(f"\n✗ 执行过程中出现错误: {e}")
print("请检查:")
print(" - 数据格式是否正确")
print(" - 模型路径是否有效")
print(" - GPU 资源是否充足")
import traceback
traceback.print_exc()
return False
def test_inference(model):
"""
使用微调后的模型进行推理测试
"""
print("\n" + "="*50)
print("推理测试")
print("="*50)
test_queries = [
"什么是机器学习?",
"解释深度学习的基本原理",
"Transformer架构有什么特点?",
]
print("\n测试问题:")
for i, query in enumerate(test_queries, 1):
print(f"\n{i}. {query}")
try:
alpaca_prompt = f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{query}
### Response:"""
if hasattr(model, '_use_transformers_directly') and model._use_transformers_directly:
response = inference_with_transformers(model, alpaca_prompt)
else:
response = model(alpaca_prompt)
print(f" 回答: {response}")
except Exception as e:
print(f" 推理错误: {e}")
if "transformers" in str(e):
print(" 提示: 请安装 transformers 库: pip install transformers torch peft accelerate")
print("\n" + "="*50)
def inference_with_transformers(model, prompt):
"""
使用 transformers 库进行 CPU/MPS 推理
"""
import torch
from lazyllm.thirdparty import AutoTokenizer, AutoModelForCausalLM
if hasattr(model, '_finetuned_model_path') and model._finetuned_model_path:
model_path = model._finetuned_model_path
else:
model_path = BASE_MODEL
print(f" 加载模型: {model_path}")
try:
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model_hf = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float32,
device_map="auto",
trust_remote_code=True
)
inputs = tokenizer(prompt, return_tensors="pt")
device = next(model_hf.parameters()).device
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model_hf.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response.split("### Response:")[-1].strip()
except Exception as e:
raise RuntimeError(f"transformers 推理失败: {e}")
# ============================================
# 主函数
# ============================================
def main():
"""
主函数:执行完整的一键微调推理流程
"""
print("\n" + "="*60)
print(" LazyLLM 一键微调推理脚本")
print("="*60)
print("\n本脚本将演示:")
print(" 1. 准备训练数据")
print(" 2. 配置模型微调")
print(" 3. 配置模型部署")
print(" 4. 执行微调流程")
print(" 5. 进行推理测试")
print("\n" + "="*60 + "\n")
# 步骤 1: 准备数据
prepare_sample_data()
# 步骤 2: 配置微调
model = setup_finetune_model()
# 步骤 3: 配置部署
model = setup_deploy_model(model)
# 步骤 4: 执行微调和部署
success = run_finetune_and_deploy(model)
if success:
# 步骤 5: 推理测试
test_inference(model)
print("\n" + "="*60)
print("脚本执行完成!")
print("="*60)
# 保留模型服务(可选)
# print("\n按 Ctrl+C 停止模型服务...")
# try:
# while True:
# pass
# except KeyboardInterrupt:
# print("\n正在停止服务...")
if __name__ == "__main__":
main()
6.12 示例十二:生成复杂应用1
prompt:
你是一名资深 AI Agent 架构师 + Python 全栈工程师。
请为我生成一个完整可运行的 Python Agent 项目,项目名称为:
《未来遗嘱模拟器(Future Will Simulator)》
这是一个除了调用在线大模型API之外【纯离线、无需任何联网工具】的 Agent 应用,用于让用户与“未来的自己”进行对话,并逐步生成一份结构化的“未来遗嘱”。
--------------------------------------------------
一、总体目标
构建一个具备以下特性的系统:
1. 启动后可在命令行进行持续交互
2. 内部采用 Agent + Skill 架构
3. 所有能力模块均以 Skill 形式存在
4. Agent 只负责任务编排与状态管理
5. 支持长期记忆
6. 最终可生成一份文字版“未来遗嘱”
--------------------------------------------------
二、整体架构要求
采用三层结构:
表现层(CLI 或 Web)
Agent 编排层
Skill 能力层
结构示意:
User
↓
Agent Controller
↓
Skills
↓
Memory
--------------------------------------------------
三、必须包含的 Skill 列表
1. PersonaManager(身份管理)
- 创建未来人格
- 维护年龄、语气、价值观、记忆等信息
2. DialogueStateTracker(对话阶段管理)
- 阶段包括:
- relationship
- values
- regrets
- future_simulation
- will_generation
3. ValueExtractor(价值信息抽取)
- 从用户文本中提取:
- value
- regret
- fear
- pride
4. MemoryStore(长期记忆)
- 分类存储所有抽取结果
5. FutureSimulator(未来推演)
- 基于记忆进行规则驱动推演
6. WillGenerator(遗嘱生成)
--------------------------------------------------
四、Skill 编写规范
每个 Skill:
- 独立 Python 文件
- 继承统一 Skill 基类
- 提供 run(self, data: dict) -> dict 方法
--------------------------------------------------
五、Agent 责任
Agent 只做三件事:
1. 接收用户输入
2. 调用合适 Skill
3. 维护 memory 与 stage
Agent 不直接写业务逻辑。
--------------------------------------------------
六、项目结构要求
future_will_simulator/
├─ app.py # 启动入口
├─ agent.py # Agent Controller
├─ memory.py # Memory 类
├─ skills/
│ ├─ base.py
│ ├─ persona.py
│ ├─ dialog_state.py
│ ├─ value_extractor.py
│ ├─ memory_store.py
│ ├─ future_simulator.py
│ └─ will_generator.py
--------------------------------------------------
七、实现要求
1. 所有代码为 Python 3
2. 不依赖网络 API
3. 可直接运行
4. 给出完整代码
5. 每个文件需有注释
6. 给出运行示例
--------------------------------------------------
八、交互示例
> I regret not caring about my health
> noted
> Family is very important
> noted
> generate
(输出遗嘱文本)
--------------------------------------------------
九、输出格式要求
1. 先给整体设计说明
2. 再给目录结构
3. 再逐文件输出完整代码
4. 最后给运行方法
--------------------------------------------------
十、风格要求
- 偏工程文档风格
- 少废话
- 可复制即用
- 不要省略代码
- 不要使用占位符
--------------------------------------------------
现在请严格按照以上要求,在文件夹./LazyLLM/example12内使用lazyllm的能力生成整个项目。
6.13 示例十三:生成复杂应用2
prompt:
你是一名精通 LazyLLM 框架的 AI 系统架构师。
请使用 LazyLLM 的 Flow、Agent、Skill、Document、Retriever 等能力,
设计并生成一个完整可运行的项目:
项目名称:
《智能标书合规审查与风险解释系统》
-------------------------------------------------
一、项目目标
输入:
- 招标文件(PDF/TXT/Markdown)
- 投标方案(PDF/TXT/Markdown)
输出:
- 结构化合规审查报告(JSON + Markdown)
-------------------------------------------------
二、系统能力
系统需要完成:
1. 文档解析
2. 条款拆分
3. 建立法规知识库(RAG)
4. 建立历史案例库(RAG)
5. 逐条合规校验
6. 风险分级
7. 输出证据引用
8. 生成最终报告
-------------------------------------------------
三、必须体现 LazyLLM 特性
- 使用 Document + Retriever 构建至少两个 RAG 库
- 使用 Flow 串联完整流程
- 至少定义 5 个 Skill
- 至少定义 3 个 Agent
- Agent 只负责任务决策
- Skill 只负责原子能力
-------------------------------------------------
四、系统架构
MasterAgent
↓
ComplianceFlow
├─ FileLoaderSkill
├─ ClauseSplitSkill
├─ RegulationRAGAgent
├─ CaseRAGAgent
├─ ComplianceJudgeAgent
├─ RiskScoreAgent
└─ ReportWriterSkill
-------------------------------------------------
五、Skill 设计
1. FileLoaderSkill
- 读取文件
- 输出纯文本
2. ClauseSplitSkill
- 将文本拆为条款列表
3. ReportWriterSkill
- 生成 Markdown + JSON 报告
-------------------------------------------------
六、Agent 设计
1. RegulationRAGAgent
- 使用法规知识库检索
2. CaseRAGAgent
- 使用案例知识库检索
3. ComplianceJudgeAgent
- 综合法规 + 案例 + 条款判断合规性
4. RiskScoreAgent
- 输出风险等级:低/中/高
-------------------------------------------------
七、Flow 设计
Flow 中按如下顺序:
FileLoaderSkill
→ ClauseSplitSkill
→ 并行:
- RegulationRAGAgent
- CaseRAGAgent
→ ComplianceJudgeAgent
→ RiskScoreAgent
→ ReportWriterSkill
-------------------------------------------------
八、项目结构
bidding_compliance_agent/
├─ app.py
├─ flow.py
├─ agents/
├─ skills/
├─ rag/
├─ data/
└─ README.md
-------------------------------------------------
九、实现要求
- 使用 LazyLLM API
- 给出完整代码
- 可运行
- 带示例数据
- 带运行说明
-------------------------------------------------
十、输出顺序
1. 系统说明
2. 架构图(ASCII)
3. 目录结构
4. 逐文件代码
5. 运行方法
现在开始生成整个项目。
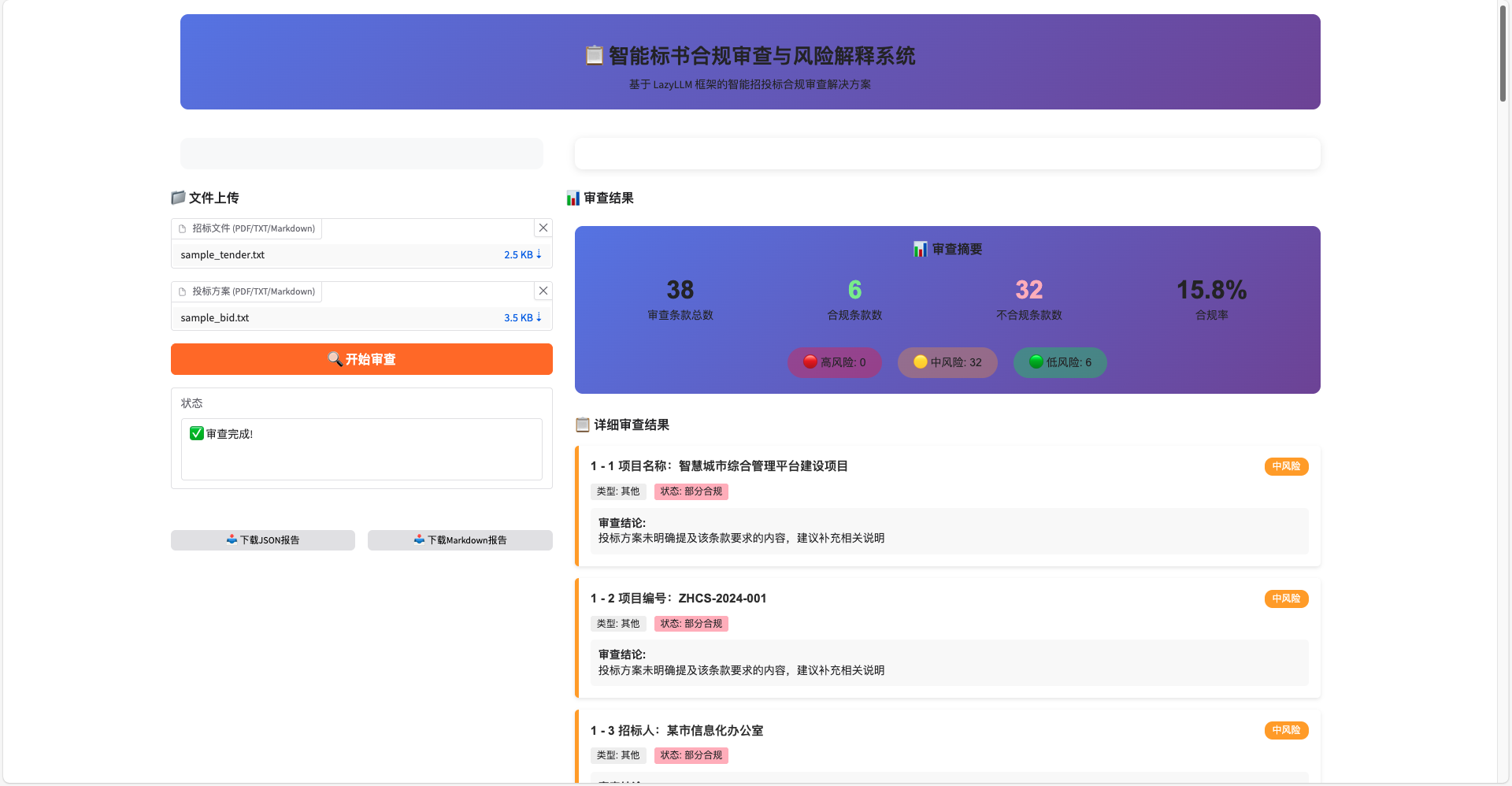
6.14 示例十四:生成复杂应用3
prompt:
论文助手多Agent系统 - LazyLLM完整实现
项目概述
使用LazyLLM框架实现一个完整的论文助手多Agent系统,包含Web界面、文档RAG系统、多角色讨论Agent、arxiv论文抓取工具和数据库管理工具。
技术栈
- 框架: LazyLLM
- 数据库: ChromaDB (向量数据库)
- 嵌入模型: 在线嵌入服务 (如智谱/百度/阿里)
- LLM: Qwen3-32B或同等能力模型
- Web框架: LazyLLM内置WebModule
核心模块要求
1. 文档RAG系统
**文档处理流程:**
- 使用lazyllm.Document加载文档
- 切分策略:使用RecursiveCharacterTextSplitter
- Chunk大小:512 tokens
- Chunk重叠:50 tokens
- 支持中文句子边界切分
- 向量化:使用cosine相似度
- 数据库:ChromaDB本地存储,路径./chroma_db
**具体配置:**
documents = lazyllm.Document(
dataset_path="/path/to/docs",
embed=lazyllm.OnlineEmbeddingModule(),
manager=False
)
# 创建Node Group用于检索
documents.create_node_group(
name="paper_chunks",
transform=lambda s: recursive_split(s, chunk_size=512, overlap=50)
)
检索器配置:
retriever = lazyllm.Retriever(
doc=documents,
group_name="paper_chunks",
similarity="cosine",
topk=5
)
2. Web界面
功能要求:
- 使用WebModule启动Web界面
- 左侧边栏:文档上传区域
- 主区域:对话界面
- 顶部:显示当前数据库状态
界面布局:
┌─────────────────────────────────────┐
│ 📁 上传文档 │ 💬 对话区域 │
│ │ │
│ [选择文件] │ 用户: xxx │
│ [开始处理] │ ─────────────── │
│ │ 助手: xxx │
│ ───────────── │ │
│ 📚 数据库状态 │ [输入框] [发送] │
│ 文档数: 0 │ │
│ 分组: - └────────────────────┘
└─────────────────────────────────────┘
3. 多角色讨论Agent系统
角色设计(4个Agent):
1. 学术导师Agent
- 角色:资深教授
- 专长:研究方向指导、方法论建议
- 语气:严谨、启发式
2. 技术专家Agent
- 角色:算法工程师
- 专长:代码实现、技术细节、实验设计
- 语气:直接、实用
3. 批判者Agent
- 角色:同行评审
- 专长:找出问题、局限性分析、改进建议
- 语气:犀利但建设性
4. 综述者Agent
- 角色:领域专家
- 专长:相关文献对比、趋势分析、创新点识别
- 语气:宏观、联系性思维
讨论机制:
- 使用Pipeline编排多Agent讨论流程
- 每个Agent看到之前的对话历史和前序Agent的观点
- 最后由Coordinator Agent综合各方观点给出最终回答
上下文管理:
- 使用ConversationManager维护多轮对话历史
- 保留最近10轮对话作为上下文
- 关键信息(如论文主题、用户研究方向)持久化存储
4. Arxiv论文抓取工具
实现要求:
1. MCPClient连接:
from lazyllm.tools import MCPClient, fc_register
arxiv_client = MCPClient(
command_or_url="https://dashscope.aliyuncs.com/api/v1/mcps/arxiv_paper/sse",
headers={"Authorization": f"Bearer {bailian_api_key}"},
timeout=10
)
mcp_tools = arxiv_client.get_tools()
2. 自定义下载工具:
import re, os, json, time
from pathlib import Path
from urllib.parse import urlparse
import requests
from lazyllm.tools import fc_register
ARXIV_ABS_RE = re.compile(r"https?://arxiv\.org/abs/([0-9]+\.[0-9]+)(v[0-9]+)?/?$")
ARXIV_PDF_RE = re.compile(r"https?://arxiv\.org/pdf/([0-9]+\.[0-9]+)(v[0-9]+)?(\.pdf)?/?$")
@fc_register("tool")
def download_arxiv_papers(urls: list[str]):
"""
Download papers from arXiv and save as PDF.
Args:
urls (list[str]): List of arxiv paper URLs
e.g., ["https://arxiv.org/abs/2503.23278"]
Returns:
str: JSON string with download status and file paths
"""
# 实现PDF下载逻辑
# 1. 规范化URL (abs转pdf)
# 2. 下载PDF到 ./papers/ 目录
# 3. 返回文件路径列表
pass
3. ArxivAgent:
arxiv_agent = ReactAgent(
llm=llm.share(),
prompt="""
【角色】你是一个论文检索与下载专家
【任务】
1. 根据用户需求搜索相关论文
2. 如果论文有价值,调用download_arxiv_papers工具下载
3. 给出推荐理由和阅读建议
【注意事项】
- 下载前确保URL是正确的PDF链接
- 一次最多下载3篇论文
- 下载后更新数据库状态
""",
tools=['download_arxiv_papers'] + mcp_tools,
stream=True
)
4. 入库流程:
- 下载完成后自动调用文档处理流程
- 将PDF加入ChromaDB向量数据库
- 在Web界面更新数据库状态显示
5. 数据库管理工具
功能设计:
1. 自然语言查询工具:
@fc_register("tool")
def query_database_info():
"""
Get current database statistics and paper groups.
Returns:
str: JSON with document count, groups, and metadata
"""
# 返回数据库统计信息
pass
@fc_register("tool")
def group_papers_by_topic(topic: str, keywords: list[str]):
"""
Group papers by topic using keywords.
Args:
topic (str): Group name/topic
keywords (list[str]): Keywords to identify papers for this group
Returns:
str: Grouping result with affected paper count
"""
# 根据关键词对已有论文进行分组
pass
@fc_register("tool")
def search_papers(query: str, topk: int = 5):
"""
Search papers in database using semantic search.
Args:
query (str): Search query
topk (int): Number of results to return
Returns:
str: List of matching papers with relevance scores
"""
# 使用向量检索搜索论文
pass
2. DBManagerAgent:
db_agent = ReactAgent(
llm=llm.share(),
prompt="""
【角色】你是论文数据库管理助手
【能力】
- 查询数据库状态(文档数量、分组情况)
- 按主题对论文进行分组
- 搜索特定论文
【规则】
- 用户用自然语言描述需求时,选择合适的工具
- 分组时要求用户提供清晰的主题和关键词
- 操作完成后报告结果
""",
tools=['query_database_info', 'group_papers_by_topic', 'search_papers']
)
6. 主系统架构
整体流程:
用户输入
↓
对话意图分类Agent(判断:闲聊/论文讨论/arxiv搜索/数据库管理)
↓
├─→ 闲聊 → 通用对话Agent
├─→ 论文讨论 → 多角色讨论Agent系统
├─→ arxiv搜索 → ArxivAgent → 自动入库
└─→ 数据库管理 → DBManagerAgent
↓
Web界面输出
主Agent配置:
main_agent = ReactAgent(
llm=llm.share(),
prompt="""
【角色】论文助手系统主控制器
【任务】分析用户意图,路由到合适的子系统
【路由规则】
- 询问论文内容、讨论研究方向 → 多角色讨论Agent
- 要求搜索、下载论文 → ArxivAgent
- 数据库相关操作(查询、分组、管理)→ DBManagerAgent
- 其他 → 通用对话
【工具】
你可以使用以下工具来路由请求:
- multi_role_discussion: 启动多角色讨论
- arxiv_search: 搜索下载论文
- db_management: 数据库管理操作
""",
tools=['multi_role_discussion', 'arxiv_search', 'db_management']
)
项目文件结构
paper_assistant/
├── main.py # 主程序入口,Web服务
├── config.py # 配置信息(API keys等)
├── agents/
│ ├── __init__.py
│ ├── main_router.py # 主路由Agent
│ ├── discussion.py # 多角色讨论Agent系统
│ ├── arxiv_agent.py # Arxiv抓取Agent
│ └── db_manager.py # 数据库管理Agent
├── tools/
│ ├── __init__.py
│ ├── arxiv_downloader.py # arxiv下载工具
│ └── db_tools.py # 数据库管理工具
├── rag/
│ ├── __init__.py
│ ├── document.py # 文档处理
│ └── retriever.py # 检索配置
├── utils/
│ ├── __init__.py
│ └── helpers.py # 辅助函数
├── papers/ # 下载的论文存储目录
├── chroma_db/ # 向量数据库目录
└── requirements.txt
依赖要求
requirements.txt:
lazyllm
chromadb
requests
关键实现注意事项
1. 所有配置从环境变量读取,不要在代码中硬编码API key
2. 使用LazyLLM的bind机制传递上下文信息
3. 文档上传后自动触发向量化流程
4. 多角色讨论使用parallel + sum模式并行生成观点
5. 所有工具使用@fc_register装饰器注册
6. 错误处理:每个Agent需要try-catch包裹,友好错误提示
7. 流式输出:WebModule配置stream=True
8. 上下文持久化:使用本地JSON文件存储对话历史
生成要求
请生成完整的、可运行的Python代码,包含所有模块的实现。代码需遵循LazyLLM最佳实践,包含适当的错误处理和注释。确保所有Agent和工具都可以被正确注册和调用。 在文件夹./LazyLLM/example14中实现
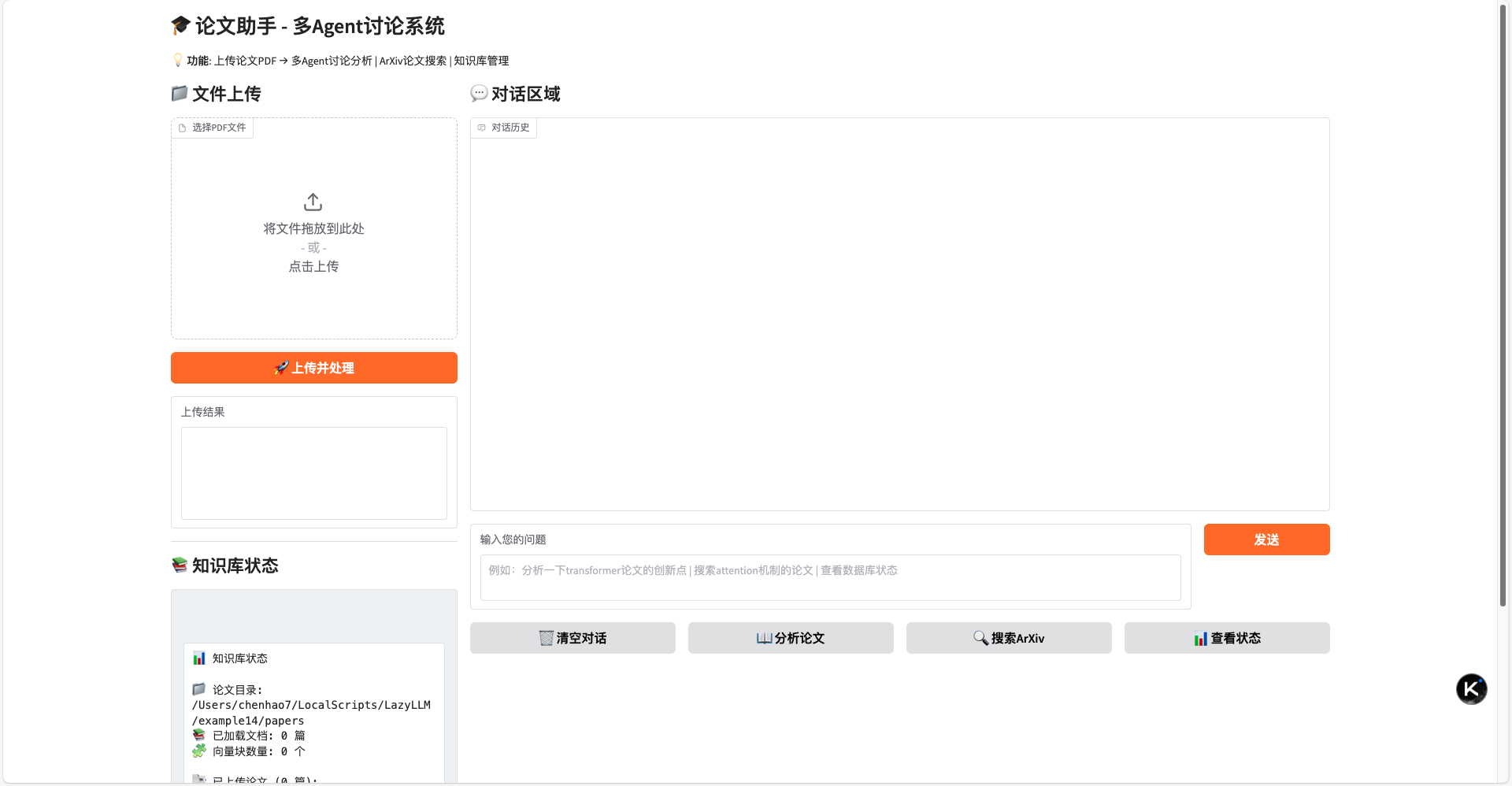
6.15 示例十五:生成复杂应用4
prompt:
你是一名精通 LazyLLM 框架的 AI 系统架构师和 Python 工程专家。
请基于 LazyLLM 的 Flow、Agent、Skill、Document、Retriever、多模态能力,设计并生成一个完整、可运行的 Web 项目:
项目名称:
《多模态证件识别与检索系统》
一、项目目标
用户通过 Web 页面上传证件照片(身份证、护照等):
系统能够:
自动识别证件类型
从图片中提取关键信息
将原始图片 + 结构化信息存入多模态 RAG 知识库
支持用户通过证件信息进行检索,并召回原始证件图片
二、输入与输出
输入
单张证件照片(jpg/png)
输出
结构化证件信息 JSON,例如:
{
"doc_type": "身份证",
"name": "张三",
"id_number": "xxxxxxxxxxxxxxxxxx",
"gender": "男",
"birth_date": "1995-02-01",
"nationality": "中国"
}
同时返回该证件在系统中的唯一ID
三、系统核心能力
系统需要实现以下能力:
图片上传
多模态证件类型识别
OCR + 语义信息抽取
结构化字段标准化
多模态向量化存储(文本 + 图片)
条件检索(按姓名 / 证件号 / 证件类型等)
返回匹配证件的原始图片与信息
四、必须体现 LazyLLM 特性
使用 Document + Retriever 构建多模态 RAG
使用 Flow 串联完整处理流程
至少定义 5 个 Skill
至少定义 3 个 Agent
Agent 负责决策与调度
Skill 负责原子能力
五、系统架构
WebUI
|
v
MainAgent
|
v
IDCardFlow
├─ ImageUploadSkill
├─ DocTypeDetectSkill
├─ OCRSkill
├─ InfoExtractSkill
├─ NormalizeSkill
├─ StoreToRAGAgent
└─ QueryRAGAgent
六、Skill 设计
ImageUploadSkill
保存图片到本地
返回路径
DocTypeDetectSkill
识别证件类型(身份证/护照/其他)
OCRSkill
从图片中提取文字
InfoExtractSkill
将 OCR 文本转为结构化字段
NormalizeSkill
字段标准化、补全、校验
七、Agent 设计
StoreToRAGAgent
负责向多模态 RAG 写入数据
QueryRAGAgent
负责检索
MainAgent
决策当前是“存储”还是“查询”
八、Flow 设计
上传存储流程
ImageUploadSkill
→ DocTypeDetectSkill
→ OCRSkill
→ InfoExtractSkill
→ NormalizeSkill
→ StoreToRAGAgent
查询流程
QueryRAGAgent
→ 返回匹配证件图片 + 信息
九、RAG 设计
使用 LazyLLM Document 构建多模态数据集
每条记录包含:
{
"text": "姓名:张三 证件号:xxxx 类型:身份证",
"image_path": "/data/img/xxx.jpg",
"metadata": {...}
}
使用 Retriever 支持 TopK 相似度检索
十、Web 前端要求
使用 FastAPI + 简单 HTML 或 Gradio
页面功能:
上传证件
展示识别结果
输入查询条件
展示检索结果(图片 + 信息)
十一、项目结构
id_doc_system/
├─ app.py
├─ flow.py
├─ agents/
│ ├─ main_agent.py
│ ├─ store_agent.py
│ └─ query_agent.py
├─ skills/
│ ├─ upload.py
│ ├─ doc_type.py
│ ├─ ocr.py
│ ├─ extract.py
│ └─ normalize.py
├─ rag/
│ └─ dataset/
├─ web/
│ └─ ui.py
└─ README.md
十二、实现要求
使用 LazyLLM API
给出完整代码
可运行
带安装说明
带启动方式
十三、输出顺序
系统说明
架构图(ASCII)
目录结构
各文件完整代码
运行步骤
现在开始生成整个项目。
7. 使用技巧与排错
-
必须明确声明“使用 LazyLLM 实现”
在需求描述中,必须显式说明:"使用 lazyllm 实现"
推荐写法: "在 xxx.py 文件中使用 lazyllm 实现……" 或:"请基于 LazyLLM 的 Flow、Agent、Skill、Document、Retriever 实现……"
否则,模型可能会生成一套自定义的框架导致无法运行。
-
先给“结构”,再给“功能”
比起一句话描述需求,更推荐: - 先说明项目目标
-
再给系统模块拆分
-
最后说明输出形式
结构越清晰,生成质量越稳定。
-
-
优先生成“最小可运行版本”
第一次生成时: "请先生成最小可运行版本(MVP)"
跑通之后,再追加需求:
-
加功能
-
加 Agent
-
加前后端
比一次性堆很多复杂能力成功率更高。
-
-
让模型在“已有代码基础上修改”
当需要调整功能时: "在当前项目基础上,仅修改 xxx.py,实现以下功能……"
避免模型整体重写导致结构漂移。
-
固定项目目录
如果模型生成结构混乱,可指定:
模型会更容易在完整项目保持前后结构一致。 -
代码无法运行,缺模块
排查步骤:
-
查看报错信息
-
将报错原样粘贴给 OpenCode
示例:
-
8. 结语
到这里,你已经完成了从环境搭建、安装 LazyLLM-Skill,到在 OpenCode 中生成并运行 LazyLLM 项目的全过程。
你会发现,真正难的从来不是“写几行代码”,而是把模型、RAG、Agent组织成一个可运行的系统。
LazyLLM 正在解决的,就是这件事。
它把 AI 应用开发中最常用、最核心的能力抽象成统一接口,让你可以专注在业务逻辑和产品想法本身,而不是底层拼装。
不论你是想做个人工具、自动化流程,还是完整的 AI 应用系统,都可以从 LazyLLM 开始尝试。
从第一个可运行的小项目开始,你会很快建立起对 AI 应用工程化的整体认知。
欢迎加入 LazyLLM 社区,一起把想法变成真正能用的 AI 应用。