第14课时:多模态指令微调与实战
本课时聚焦多模态指令微调,讨论模型如何同时理解图像与文本,并在受任务约束的条件下输出可评估的答案。与纯文本 SFT 相比,多模态微调的核心难点不只是“会不会回答”,而是“回答是否真正依赖了视觉证据”。
因此,本章分为两个部分展开。前半部分介绍多模态指令数据的基本形态,包括从图像描述到 VQA 的演化、多模态 CoT 数据和交错图文数据;后半部分结合 LazyLLM 的完整实验流程,演示如何使用大模型生成高质量医学影像训练数据,再微调小模型以增强其医学视觉问答能力。
1 从 Caption 到 VQA:Visual Instruction Tuning 的演化路径
在多模态大模型的发展过程中,视觉指令微调并非一蹴而就,而是经历了从“被动描述”到“主动理解与决策”的逐步演化。本节的目标是回答两个问题:
- 为什么 VQA 是多模态指令微调的重要起点
- 为什么它比单纯的图像描述更接近真实任务

1.1 Image Caption:从“看见”到“描述”
Image Captioning(图像描述) 是最早的视觉-语言任务之一,其目标是让模型将图像内容转化为自然语言描述。
任务形式:
示例:
Input:一张胸部 CT 图像
Output:A CT scan of the chest showing bilateral lung opacities.
特点与局限:
- 学会基础视觉语义对齐,如 object、region、attribute
- 建立“视觉 -> 语言”的映射能力
- 输出自由度高,缺乏明确任务约束
- 难以判断描述是否抓住了当前任务真正关心的信息
- 无法直接支撑决策类场景
关键结论是:Image Caption 解决的是“图像里有什么”,而不是“基于图像应作出什么判断”。
1.2 Visual Question Answering(VQA):从“描述”到“回答问题”
为了让模型具备目标导向的视觉理解能力,研究者提出了 Visual Question Answering(VQA)。它在图像之外增加了明确的问题约束,使模型必须围绕具体任务作答。
任务形式:
示例(医学场景):
Image:脑部 CT
Question:Are regions of the brain infarcted?
Answer:Yes
与 Caption 相比,VQA 引入了显式的语言条件 Question,迫使模型:
- 聚焦图像中的特定区域或属性
- 根据问题语义筛选视觉证据
- 输出可验证、可评估的结果
VQA 相较 Caption 的核心差异可以总结如下:
| 维度 | Image Caption | VQA |
|---|---|---|
| 输出形式 | 自由文本 | 受限答案 |
| 是否有任务目标 | 否 | 是 |
| 是否便于自动评估 | 较难 | 较容易 |
| 是否支持决策任务 | 否 | 是 |
关键转变在于:模型不再被要求“说得多”,而是被要求“答得对”。
1.3 从 VQA 到 Visual Instruction Tuning
虽然 VQA 在形式上看起来只是问答任务,但从训练机制上看,它已经具备了视觉指令微调所需的关键成分。
第一,VQA 中的问题本身就是一种显式指令。例如在医学场景中,问题往往并不是泛泛而谈,而是要求模型完成某种判断:
Is there evidence of hemorrhage?Does the gallbladder appear distended?
这些问题本质上都可以理解为:
请根据图像完成一个受约束的判断任务。
第二,模型输出必须同时依赖两种输入:
- 视觉输入,即图像中的区域、器官、病灶或结构信息
- 文本输入,即问题所规定的关注点和回答目标
这意味着模型学习的其实是一个跨模态条件生成过程:
其中:
- \(\text{Image}\) 表示输入图像及其视觉特征
- \(\text{Question}\) 表示文本问题或任务指令
- \(\text{Answer}\) 表示模型最终输出的回答
- \(P(\cdot \mid \cdot)\) 表示在图像和问题共同条件下的生成概率
第三,在许多专业 VQA 数据集中,输出空间是相对标准化的,例如:
Yes / No- 器官名称
- 病灶类型
- 数值型回答
这种标准化输出使模型行为更稳定,也更便于评测与比较。
因此可以说,VQA 是多模态指令微调的“最小可控形态”。它虽然还不等于完整的多模态 Agent,但已经完整体现了 Instruction Following 的本质。
1.4 Visual Instruction Tuning 的统一视角
从更高层次看,Caption、VQA 与 Visual Instruction 并不是彼此割裂的任务,而是处在同一条能力演化链条上:
Image Caption
↓
Visual Question Answering
↓
Visual Instruction Following
↓
Multimodal Reasoning & Agent
这条链条可以理解为三个阶段:
- Caption 解决视觉与语言的初步对齐问题
- VQA 解决在任务约束下进行选择与判断的问题
- Visual Instruction Tuning 解决更复杂的执行、规划与推理问题
在本课时中,我们选择 VQA-RAD 作为实验切入点,正是因为它同时满足以下条件:
- 数据规模可控
- 任务形式清晰
- 医学决策价值高
- 非常适合验证多模态微调效果
2 多模态指令数据:CoT 与交错图文
在多模态指令微调中,数据质量往往比模型规模更重要。相比简单地把“图像 + 文本”直接拼接,高质量多模态数据更关心两件事:
- 模型如何进行推理
- 模型如何在多轮图像与文本交互中逐步形成判断
围绕这两个问题,本节重点介绍两类数据形式:
- 多模态 Chain-of-Thought(CoT)数据
- 交错图文(Interleaved Image-Text)数据
2.1 经典图文数据集
这类数据集主要用于完成视觉与文本之间的基础对齐,是训练模型“看图说话”、图文理解和跨模态生成的基础。
| 数据集 | 领域 | 规模 | 特点 | Schema |
|---|---|---|---|---|
| LAION-5B | 通用多模态 | 58.5 亿图文对 | 全球规模最大的开源图文对数据集之一,含 URL、文本与相似度分数 | {"url": str, "caption": str, "similarity": float} |
| ScienceQA | 科学教育 | 2.1k 样本 | 多模态科学问答,包含图像、上下文和详细 CoT 解析 | {"image": img, "hint": str, "solution": str, "lecture": str} |
| ShareGPT4V | 高质量描述 | 1.2M 样本 | 使用 GPT-4V 生成精细图像描述,适合提升细节刻画能力 | {"image": str, "conversations": List[Dict]} |
| OCR-VQA | OCR | 20 万图像 | 聚焦图像中文字理解,适合提升 OCR 与图文问答能力 | {"image_id": int, "questions": List[str], "answers": List[str]} |
这些数据集共同完成的,是“视觉语义对齐”的基础工作。但如果希望模型完成更强的视觉决策任务,仅靠这类数据通常还不够。
2.2 专业垂直领域多模态数据集
在专业领域中,多模态任务不再只是“识别图里有什么”,而是需要把图像证据与领域知识结合起来进行判断。下面列出几个典型数据集。
- PathVQA:病理影像多模态问答。模型必须识别病理切片中的细胞结构,再回答专家提出的问题。
- GeoQA:几何逻辑多模态问答。模型需要理解图形结构并结合题干完成推理。
{
"image": "geometry_05.png",
"subject": "已知圆 O 的半径为 5,求阴影部分的面积。",
"comment": ["识别圆形与切线", "应用勾股定理", "计算扇形减去三角形"],
"answer": "25π/4"
}
- DocVQA:文档理解多模态。模型需要同时具备 OCR、版面分析和语义问答能力。
{
"image": "invoice_00023.png",
"question": "What is the total amount due on this invoice?",
"answer": "1,245.00 USD"
}
- ChartQA:图表理解与数值推理。模型要从图像中读取数值信息并执行比较、排序或计算。
{
"image": "sales_chart_12.png",
"query": "Which year shows the largest increase in revenue compared to the previous year?",
"label": "2019"
}
这些垂直数据集说明,多模态能力真正有价值的地方,往往不在通用描述,而在专业推理。
2.3 为什么需要多模态 Chain-of-Thought(CoT)
在标准 VQA 任务中,训练样本通常采用如下映射:
这种监督方式虽然能让模型学会“输出正确答案”,但存在明显局限:
- 模型可能依赖语言先验而不是视觉证据
- 推理过程完全隐式,难以判断模型是否真的看懂了图像
- 在医学、工业等高风险场景中,容易产生“自信但错误”的回答
多模态 CoT 的目标是将人类的推理路径显式写入训练样本中,即:
通过把中间推理步骤作为监督信号,模型不仅学习“答案是什么”,还学习:
- 应该关注哪些视觉现象
- 如何将视觉证据映射到领域语义
- 如何由证据推出最终结论
多模态 CoT 的核心价值,不是让模型输出更长文本,而是要求其推理路径显式依赖图像证据。
2.4 多模态 CoT 的设计原则
在实际构造多模态 CoT 数据时,至少应遵循以下三个原则。
2.4.1 推理必须可追溯到图像证据
错误示例:
根据医学常识,脑梗塞通常会出现低密度影。
正确示例:
在 CT 图像中,右侧基底节区可见低密度灶,该影像特征通常对应缺血性脑梗塞。
两者的本质区别在于,后者把判断与图像中的具体证据绑定在了一起。
2.4.2 CoT 应突出任务所需的最短推理链
多模态 CoT 的目标不是生成完整诊断报告,而是保留完成当前任务所需的关键中间步骤。对大多数 VQA 场景而言,2 到 4 步推理通常已经足够:
- 识别关键视觉现象
- 解释这些现象对应的领域语义
- 给出最终判断
过长的推理文本容易引入噪声,反而会降低训练稳定性。
2.4.3 最终答案应结构化、可提取
在训练数据中,应将 Reasoning 与 Answer 明确区分,例如:
这样做有三个好处:
- 推理内容可作为辅助监督信号
- 最终答案可作为主要优化目标
- 评测阶段可直接抽取标准答案
2.5 交错图文(Interleaved Image-Text)
标准 VQA 往往假设一张图就足以回答问题,但在真实场景中,这个假设经常不成立。例如:
- 多切片 CT / MRI
- 多视角 X-ray
- 同一器官在不同时刻或不同平面的图像
医生阅片时,往往是反复切换图像与文字信息,逐步形成判断。交错图文正是在模拟这一认知过程。
其核心结构通常如下:
医学场景下的一个简单示例如下:
<image>
Axial CT slice shows hypodensity in the right basal ganglia.
<image>
Coronal view confirms the extent of the lesion.
Question: Is the infarction acute?
交错图文的关键并不是“放多张图”,而是用文本把不同图像中的观察串联起来,模拟人类逐步查看、逐步归纳的过程。
2.6 图文交错数据的简单抽取示例
下面这段代码展示如何从一个简短的图文交错片段中抽取图片链接,并构造成可用于训练的数据字段。
import re
def describe_image(url):
# 模拟一个图像描述函数(真实场景中可由 VLM 生成)
return "The chest X-ray shows signs of possible pneumonia."
paragraph = """
A chest X-ray is commonly used to examine the lungs and heart.
See the image here: https://fake-med-data.org/images/chest_xray_001.png
In this image, the patient shows signs of possible pneumonia.
"""
pattern = r"https?://\\S+\\.png"
image_urls = re.findall(pattern, paragraph)
text = paragraph.strip()
answer = "The X-ray shows signs consistent with pneumonia."
describe = [describe_image(url) for url in image_urls]
print({
"text": text,
"answer": answer,
"describe": describe
})
输出示例:
{
'text': 'A chest X-ray is commonly used to examine the lungs and heart.\nSee the image here: https://fake-med-data.org/images/chest_xray_001.png\nIn this image, the patient shows signs of possible pneumonia.',
'answer': 'The X-ray shows signs consistent with pneumonia.',
'describe': ['The chest X-ray shows signs of possible pneumonia.']
}
这段代码本身并不复杂,但体现了一个很重要的工程思想:原始图文混合内容并不能直接作为训练数据使用,必须先经过结构化整理,才能进入后续的指令微调流程。
2.7 常见数据格式设计
在工程实践中,我们通常把前面的思想统一映射为几类标准数据格式。
2.7.1 标准 VQA 数据
{
"messages": [
{
"role": "user",
"content": "<image> Are regions of the brain infarcted?"
},
{
"role": "assistant",
"content": "Yes"
}
],
"images": ["ct_001.jpg"]
}
这种形式适合基础多模态对齐训练,但对推理路径的约束较弱。
2.7.2 带多模态 CoT 的指令数据
{
"messages": [
{
"role": "user",
"content": "<image> Are regions of the brain infarcted?"
},
{
"role": "assistant",
"content": "Reasoning: The CT image shows a hypodense region in the basal ganglia, which is a typical imaging feature of ischemic infarction.\nAnswer: Yes"
}
],
"images": ["ct_001.jpg"]
}
这种格式通过显式推理过程,迫使模型将回答建立在视觉证据之上。
2.7.3 交错图文样本
{
"messages": [
{
"role": "user",
"content": "<image> Axial CT slice.\n<image> Coronal CT slice.\nQuestion: Does the gallbladder appear distended?"
},
{
"role": "assistant",
"content": "Answer: Yes"
}
],
"images": ["ct_axial.jpg", "ct_coronal.jpg"]
}
这种格式适用于多视角、多阶段视觉理解任务,也为后续复杂多模态推理打下基础。
3 用 LazyLLM 玩转医学多模态推理增强(Img + PPL)
在真实医学场景中,一个典型难题是:
- 小模型成本低,但专业能力不够稳定
- 大模型能力强,但推理与部署成本较高
因此,一个非常自然的思路是:
用大模型生成高质量训练数据,再用这些数据去提升小模型。
本实验的核心目标就是:
3.1 数据集简介
本实验使用医学影像 VQA 数据集:
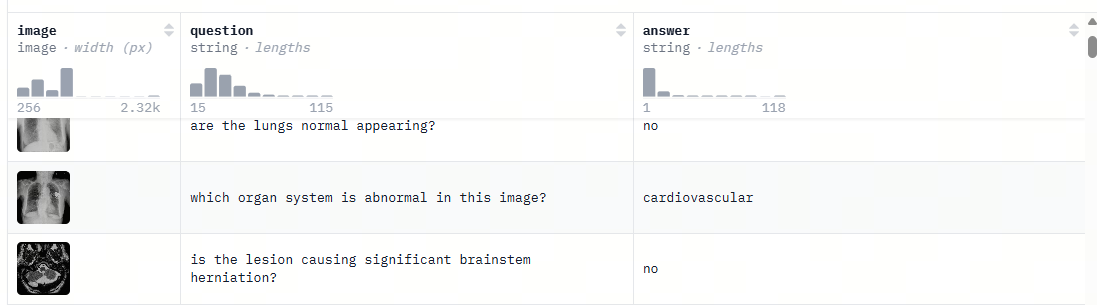
该数据集面向放射影像问答场景,每条样本通常包含一张医学图像、一个问题和一个标准答案。
3.1.1 数据结构
这里的 image 在加载后是内存中的 PIL.Image 对象,实际训练前需要先保存为本地文件。
3.1.2 数据规模
| Split | 数量 |
|---|---|
| Train | 1793 |
| Test | 451 |
这是一个相对小规模但非常适合教学实验的数据集:规模不大,便于复现;任务明确,便于验证增强前后的差异。
3.2 数据处理与增强 Pipeline
本实验的核心思想并不是直接拿原始 question -> answer 样本去训练,而是先通过更强的 VLM 生成带有推理过程的增强数据,再将增强后的结果用于 SFT。
整个流程可以概括为:
原始 VQA-RAD
↓
保存图片并转换为 instruction/input/output
↓
使用 img2qa pipeline 生成 reasoning-enhanced data
↓
直接用于 VLM SFT
3.2.1 数据下载与格式转换
脚本首先加载 VQA-RAD 数据集:
随后将每条样本转换为统一格式:
对应的核心代码如下:
def prepare_dataset():
dataset = load_dataset("flaviagiammarino/vqa-rad")
def process_split(split_name, save_path):
data_out = []
split = dataset[split_name]
for i, sample in enumerate(split):
img = sample["image"].convert("RGB")
question = sample["question"]
answer = sample["answer"]
img_path = IMAGE_DIR / f"{split_name}_{i}.jpg"
img.save(img_path)
data_out.append({
"instruction": question,
"input": str(img_path),
"output": answer
})
这一步完成了三件事:
- 把
PIL.Image保存到本地,便于训练和评测复用 - 统一图像路径字段为
input - 把问答样本转成更适合 SFT 的结构化格式
3.2.2 图片保存与预处理
在一键脚本中,图像会先落盘,再交给后续 img2qa 流水线统一处理。这样做有几个工程层面的好处:
- 图像文件可以在训练、评测和调试中重复使用
- 可以对所有图像施加统一的缩放规则
- 有利于控制显存占用
- 可以提升多模态训练的稳定性
本实验中,在流水线里统一将图片缩放到 336 × 336。这个尺寸一方面足以保留多数影像的主要结构信息,另一方面也有助于控制推理与训练成本。
3.2.3 生成增强数据
增强阶段的核心算子是 build_img2qa_pipeline。它会根据图片和问题,生成带推理过程的增强答案,并直接写回训练集。
示例形式如下:
{
"query": "Is the mass hyperintense or hypointense?",
"answer": "Reasoning: ... Therefore, hyperintense."
}
对应的关键代码如下:
model = lazyllm.TrainableModule("Qwen2.5-VL-32B-Instruct").deploy_method(
lazyllm.deploy.vllm,
openai_api=True
)
ppl = build_img2qa_pipeline(
model=model,
gen_prompt=gen_prompt,
image_key='input',
context_key='instruction',
img_resize=True,
size=(336, 336)
)
这段代码体现了几个重要设计:
- 使用
Qwen2.5-VL-32B-Instruct作为教师模型生成增强数据 - 用
image_key='input'指明图像路径字段 - 用
context_key='instruction'指明问题文本字段 - 开启
img_resize=True,并统一到size=(336, 336)
增强数据的价值在于,它不再只给出短答案,而是加入了从视觉观察到结论的中间推理,训练信号比原始 VQA 更丰富。
3.2.4 增强 Prompt 设计
本实验中,增强质量高度依赖教师模型的 prompt。脚本中的 gen_prompt 明确要求模型不要简单重复答案,而是重建通向答案的推理过程。
其设计目标主要有三点:
- 强制模型先做视觉观察,再做逻辑整合
- 把最终短答案嵌入完整解释之中
- 避免只输出
Yes / No这种信息量过低的结果
从训练角度看,这相当于把原本稀疏的监督信号扩展为更丰富的 reasoning-enhanced supervision,使学生模型更容易学到“为什么这样答”,而不只是“答案是什么”。
3.2.5 直接进入 SFT 训练
脚本不会额外执行质量评分过滤,也不会再做一次格式转换,而是直接基于训练集中的以下字段进入 VLM 微调:
这种设计使得整个流程非常简洁:增强完的数据就是训练数据。但它也意味着,增强质量更依赖教师模型本身。如果教师生成内容存在系统性偏差,学生模型也会继承这些偏差。
3.3 模型微调(SFT)
本实验中用于微调的学生模型是 Qwen2.5-VL-3B-Instruct。一键启动脚本中的完整模型构建代码如下:
def build_sft_model(model_path):
return (
lazyllm.TrainableModule(model_path, type='vlm', target_path=BASE_DIR)
.mode("finetune")
.trainset(str(TRAIN_JSON))
.finetune_method(
(finetune.llamafactory, {
"learning_rate": 1e-5,
"cutoff_len": 1024,
"max_samples": 10000,
"preprocessing_num_workers": 1,
"val_size": 0.1,
"per_device_train_batch_size": 12,
"num_train_epochs": 3.0,
"gradient_accumulation_steps": 10,
"overwrite_cache": False,
})
)
.prompt(dict(system="You are a medical assistant, answer the question, answer no if you are not sure about the result.", drop_builtin_system=True))
)
这里的核心参数含义如下:
learning_rate = 1e-5:学习率,控制参数更新步长。由于是小数据集上的多模态微调,设置较小学习率更稳妥,可减少对原始能力的破坏。cutoff_len = 1024:最大上下文长度,限制单条样本可参与训练的 token 数量。max_samples = 10000:训练时允许使用的最大样本数。由于当前训练集不到 2000 条,因此这一参数在本实验中更像是上限保护。preprocessing_num_workers = 1:数据预处理进程数。小数据实验中设置为 1 更便于稳定复现。val_size = 0.1:从训练集划出 10% 用作验证集。per_device_train_batch_size = 12:每张设备上的 batch size。num_train_epochs = 3.0:完整训练 3 个 epoch。gradient_accumulation_steps = 10:梯度累积步数,用于在显存有限时增大等效 batch size。overwrite_cache = False:不覆盖预处理缓存,便于重复运行时复用缓存结果。
其中,一个常被忽略但很重要的量是等效 batch size:
其中:
- \(B\) 表示
per_device_train_batch_size - \(G\) 表示
gradient_accumulation_steps - \(\text{Effective Batch Size}\) 表示单设备上的等效 batch size
在本实验中:
这意味着尽管单步只处理 12 条样本,但通过梯度累积,模型最终等效于以 120 条样本的规模更新一次参数,有助于提升小数据训练时的稳定性。
从整体配置看,这是一套偏保守但比较稳妥的小数据 VLM 微调参数组合:学习率较低、epoch 不高、梯度累积较大,更关注稳定适应而不是激进更新。
3.4 自动评测方法
完成微调后,实验分别对:
- 原始
Qwen2.5-VL-3B-Instruct基座模型 - SFT 后的
Qwen2.5-VL-3B-Instruct
在同一测试集上执行推理,并用更强的文本模型进行自动评分。
评分规则非常直接:
- 如果模型预测与标准答案语义一致,记为 1
- 否则记为 0
自动评分器的核心实现如下:
scorer = (
lazyllm.TrainableModule("qwen3-14b").deploy_method(
lazyllm.deploy.vllm,
openai_api=True
)
.prompt("""
Task: Accuracy Check.
Judge if the "Prediction" logically supports and includes the "Standard Answer".
1 = Correct & Consistent
0 = Incorrect or Irrelevant
Only output JSON: {"score": 0 or 1}
""")
.formatter(JsonFormatter())
.start()
)
这种评测方式本质上是在近似计算:
其中:
- \(N_{\text{correct}}\) 表示得分为 1 的样本数
- \(N\) 表示测试样本总数
- \(\text{Accuracy}\) 表示测试集上的语义一致性准确率
由于医学 VQA 中很多答案较短,直接做字符串匹配容易过于严格,因此这里采用 LLM 评审方式来判断语义一致性,通常比字面匹配更合理。
3.5 实验结果
实验输出如下:
=== infer (infer_score.json) ===
测试总数: 451
1 的数量: 197 (43.68%)
0 的数量: 254 (56.32%)
最终得分: (43.68%)
=== sft (sft_score.json) ===
测试总数: 451
1 的数量: 209 (46.34%)
0 的数量: 242 (53.66%)
最终得分: (46.34%)
3.5.1 定量结果
| 方法 | 总数 | 正确 | 错误 | 准确率 |
|---|---|---|---|---|
| Infer(微调前) | 451 | 197 | 254 | 43.68% |
| SFT(微调后) | 451 | 209 | 242 | 46.34% |
3.5.2 提升分析
从结果上看,准确率由 43.68% 提升到 46.34%,提升了 2.66 个百分点。对应到样本层面:
- 正确样本数增加了 12 条
- 错误样本数减少了 12 条
这个提升幅度并不算大,但在当前实验设置下是合理的,原因主要有以下几点:
- 数据集规模较小,训练上限受限
- 学生模型本身只有 3B 规模,医学专业视觉能力有限
- 增强数据虽然更丰富,但并没有再做额外质量过滤
因此,这一结果更适合被理解为:
使用教师模型生成 reasoning-enhanced 数据,能够让小型 VLM 在医学 VQA 上获得可观测但有限的增益。
3.6 结果对比示例
下面给出一个更直观的案例。
微调前,基模型错误地按常识回答“肾的位置”,忽略了图像中其实看不到肾:
{
"instruction": "where are the kidney?",
"input": "/vqa_rad_simple/images/test_4.jpg",
"output": "not seen here",
"prediction": "In this CT scan of the abdomen, the kidneys are located in the lower back region, on either side of the vertebral column. The right kidney is typically positioned higher than the left due to the liver between them.",
"score": 0
}
微调后,模型能够更贴近图像本身作答,判断图片中没有看到肾:
{
"instruction": "where are the kidney?",
"input": "/vqa_rad_simple/images/test_4.jpg",
"output": "not seen here",
"prediction": "The kidneys are not visible in this CT scan image provided.",
"score": 1
}
这个例子非常典型。微调前的模型更依赖语言常识,回答的是“肾通常在哪里”;微调后的模型则更依赖当前图像证据,回答的是“这张图里是否看到了肾”。这正是多模态增强训练想要达到的效果。
3.7 总结
本实验展示了一个典型的多模态能力增强范式:
- 使用专业数据集构建基础 VQA 样本
- 用更强的视觉语言模型生成带推理过程的增强训练数据
- 用增强数据对较小的 VLM 做 SFT
- 用统一测试集和自动评分器比较增强前后的效果
从结果看,模型在医学影像任务上的预测能力获得了小幅提升。虽然提升幅度有限,但它验证了一个重要结论:
高质量教师数据可以在不扩大学生模型规模的情况下,帮助其更稳定地依据视觉证据作答。
本章涉及的完整代码位于:
这一思路不仅适用于 VQA-RAD,也可以迁移到病理影像、文档理解、图表推理等其他多模态垂直任务中。下一步若希望继续提升效果,可以从三个方向入手:
- 对增强样本增加质量过滤与人工抽检
- 引入更强或更贴近领域的教师模型
- 在训练目标中显式区分推理文本与最终答案
参考文献
Rewriting Image Captions for Visual Question Answering Data Creation