构建带聊天历史的问答应用
问答系统的一个关键挑战是处理对话上下文。本教程展示如何为 RAG 应用添加记忆功能,使其能够处理依赖于聊天历史的后续问题。
我们将使用 LazyLLM 框架构建一个能够有效处理多轮对话的会话式 RAG 系统。
通过本节您将学习到 LazyLLM 的以下要点
- 如何结合[Document]加载和管理带有嵌入的文档
- 如何使用[Retriever]基于相似度检索相关文档
- 如何使用[Reranker]对检索到的文档进行重新排序以提高相关性
- 如何结合[ReactAgent]创建可以进行多次检索迭代的智能体
设计思路
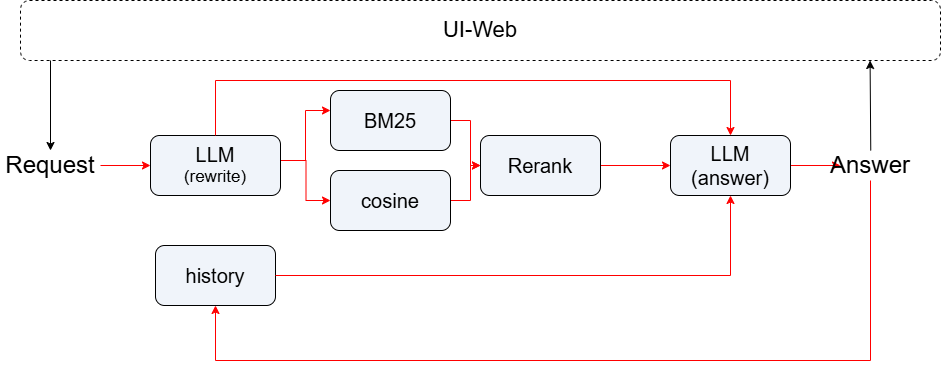
多轮对话式RAG系统,核心思路是通过上下文感知的问题重写,将依赖历史的问题转化为独立可检索的查询。我们首先利用最近几轮对话历史,调用LLM重写当前问题;然后采用向量检索与BM25混合策略并行召回相关文档片段;接着用重排序模型筛选最相关的内容;最后将重写后的问题、检索上下文和对话历史一并输入LLM生成答案。整个流程基于LazyLLM的pipeline构建,对话历史被显式维护并限制长度,避免信息过载。并且使用fc_register将函数封装为工具函数,支持被ReactAgent调用。最终通过Web界面提供交互入口,实现端到端的多轮问答体验。
环境配置
依赖
import os
import tempfile
from typing import List, Dict, Any
import lazyllm
from lazyllm import pipeline, parallel, bind, fc_register
from lazyllm import Document, Retriever, Reranker, SentenceSplitter, OnlineEmbeddingModule
上下文依赖挑战
会话式 RAG 的一个关键挑战在于,用户消息和 LLM 的响应并不是唯一的上下文形式。用户消息可能会引用之前对话的部分内容,这使得单独理解它们变得具有挑战性。
例如,下面的第二个问题依赖于第一个问题的上下文:
第二个问题"这种方法有哪些常见的扩展?"如果没有第一个问题的上下文是模糊的。我们的系统需要理解"这种方法"指的是"思维链提示"。
聊天历史的状态管理
为了处理这种情况,我们需要基于聊天历史来理解问题上下文。让我们构建我们的会话式 RAG 系统 (ConversationalRAGPipeline): 初始化时自动创建对话历史存储和RAG 流水线, 其中docs_path用于指定知识库文档目录
class ConversationalRAGPipeline:
"""基于 LazyLLM 组件的多轮会话 RAG 管道"""
def __init__(self, docs_path: str = None):
self.chat_history = []
self.docs_path = docs_path or self._create_sample_docs()
self.pipeline = None
self.init_pipeline()
首先,我们设置文档和嵌入:
def init_pipeline(self):
"""初始化 RAG 管道"""
# 创建文档和嵌入
documents = Document(
dataset_path=self.docs_path,
embed=OnlineEmbeddingModule(
source="qwen",
type="embed",
embed_model_name="text-embedding-v1"
),
manager=False
)
documents.create_node_group(
name="sentences",
transform=SentenceSplitter,
chunk_size=512,
chunk_overlap=100
)
接下来,我们创建一个上下文化提示contextualize_prompt,用于基于聊天历史重新表述问题。同时我们为RAG创建一个提示rag_prompt,使其能正确理解指令并生成符合要求的回答:
然后我们构建具有并行检索和重排序的主要 RAG 管道,其中包括对问题的双路并行检索(基于余弦相似度和基于BM25)以及结果重排序:
with pipeline() as ppl:
# Parallel retrieval
with parallel().sum as ppl.prl:
ppl.prl.retriever1 = Retriever(
documents,
group_name="sentences",
similarity="cosine",
topk=3
)
ppl.prl.retriever2 = Retriever(
documents,
"CoarseChunk",
"bm25_chinese",
0.003,
topk=2
)
# Reranking
ppl.reranker = Reranker(
"ModuleReranker",
model=OnlineEmbeddingModule(type="rerank", source="qwen"),
topk=3,
output_format='content',
join=True
) | bind(query=ppl.input)
# LLM generates answer
ppl.llm = lazyllm.OnlineChatModule(
source="deepseek",
stream=False,
timeout=60
).prompt(lazyllm.ChatPrompter(rag_prompt, extra_keys=["context_str", "chat_history"]))
self.pipeline = ppl
def contextualize_question(self, question: str) -> str:
"""Reformulate question based on chat history"""
if not self.chat_history:
return question
...
return question
def _format_chat_history(self, messages: List[Dict], max_turns: int = 3) -> str:
"""Format chat history"""
history = []
# Take recent conversation turns
for msg in messages[-max_turns * 2:]: # Each turn includes question and answer, so multiply by 2
if msg["role"] == "user":
history.append(f"User: {msg['content']}")
elif msg["role"] == "assistant":
history.append(f"Assistant: {msg['content']}")
return "\n".join(history)
聊天方法处理对话流程,首先ontextualize_question重构我们的问题, _format_chat_history构建历史对话文本,并使用pipeline构建rag管道,随后更新聊天历史:
智能体
智能体利用 LLM 的推理能力在执行过程中做出决策。使用智能体允许你将更多的检索过程决策权交给系统。虽然它们的行为比上述"链式"处理更难预测,但它们能够执行多个检索步骤来服务于一个查询,或者对单个搜索进行迭代。
下面我们使用 LazyLLM 的 ReactAgent 组装一个最小的 RAG 智能体:
@fc_register("tool")
def conversational_rag_chat(question: str) -> str:
"""
Multi-turn conversational RAG tool
Args:
question (str): User question
Returns:
str: RAG system's answer
"""
global rag_system
if rag_system is None:
rag_system = ConversationalRAGPipeline()
return rag_system.chat(question)
def create_rag_agent():
"""Create RAG agent"""
agent = lazyllm.ReactAgent(
llm=lazyllm.OnlineChatModule(source="deepseek", timeout=60),
tools=["conversational_rag_chat"],
max_retries=3,
return_trace=False,
stream=False
)
return agent
与我们之前的实现的主要区别在于,这里不是以最终生成步骤结束运行,而是工具调用可以循环回去收集更多信息。然后智能体可以使用检索到的上下文回答问题,或者生成另一个工具调用以获取更多信息。
让我们用一个通常需要迭代序列检索步骤的问题来测试:
注意智能体: 1. 生成查询以搜索任务分解的标准方法 2. 收到答案后,生成第二个查询以搜索其常见扩展 3. 在收到所有必要的上下文后,回答问题
运行应用
启动 Web 界面:
然后访问 http://localhost:8849 通过 Web 界面与会话式 RAG 系统进行交互。
完整代码
点击展开完整代码
import os
import tempfile
from typing import List, Dict, Any
import lazyllm
from lazyllm import pipeline, parallel, bind, fc_register
from lazyllm import Document, Retriever, Reranker, SentenceSplitter, OnlineEmbeddingModule
class ConversationalRAGPipeline:
"""Multi-turn conversational RAG pipeline based on LazyLLM components"""
def __init__(self, docs_path: str = None):
self.chat_history = []
self.docs_path = docs_path or self._create_sample_docs()
self.pipeline = None
self.init_pipeline()
def _create_sample_docs(self) -> str:
"""Create sample documents directory"""
temp_dir = tempfile.mkdtemp(prefix="rag_docs_")
# Create sample documents
sample_docs = {
"task_decomposition.txt": """
Task decomposition is a technique for breaking down complex tasks into smaller, more manageable subtasks.
Chain of Thought (CoT) prompting has become a standard technique for enhancing model performance on complex tasks.
The model is instructed to "think step by step" to utilize more test-time computation to decompose hard tasks into smaller and simpler steps.
CoT transforms big tasks into multiple manageable tasks and sheds light into an interpretation of the model's thinking process.
""",
"tree_of_thoughts.txt": """
Tree of Thoughts (ToT) extends CoT by exploring multiple reasoning possibilities at each step.
It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure.
The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier or majority vote.
""",
"decomposition_methods.txt": """
Common task decomposition methods include:
1) Using simple prompting with LLM like "Steps for XYZ" or "What are the subgoals for achieving XYZ?"
2) Using task-specific instructions like "Write a story outline" for writing a novel
3) Incorporating human inputs to guide the decomposition process
""",
"conversational_rag.txt": """
Conversational RAG systems need to handle chat history and context.
Key challenges include reformulating questions based on conversational context,
maintaining relevant chat history, and generating contextually relevant responses.
The system needs to understand pronoun references and contextual dependencies.
""",
"agent_rag.txt": """
Agent-based RAG systems can iterate over multiple retrieval steps.
Unlike chains that generate at most one query per input, agents can execute multiple retrieval steps to serve a query,
or iterate on a single search to gather more comprehensive information.
Agents leverage reasoning capabilities to make decisions during execution.
"""
}
for filename, content in sample_docs.items():
with open(os.path.join(temp_dir, filename), 'w', encoding='utf-8') as f:
f.write(content.strip())
print(f"Created sample documents directory: {temp_dir}")
return temp_dir
def init_pipeline(self):
"""Initialize RAG pipeline"""
# Create documents and embeddings
documents = Document(
dataset_path=self.docs_path,
embed=OnlineEmbeddingModule(
source="qwen",
type="embed",
embed_model_name="text-embedding-v1"
),
manager=False
)
documents.create_node_group(
name="sentences",
transform=SentenceSplitter,
chunk_size=512,
chunk_overlap=100
)
# Define question rewriting prompt
contextualize_prompt = """You are an assistant that helps rewrite questions. Your task is to:
1. Analyze the user's chat history
2. Understand the latest question
3. If the question depends on historical context, rewrite it as a standalone understandable form
4. If the question is already standalone, return the original question
5. Only return the rewritten question, do not add any explanations
Example:
History: "User: Tell me about John\nAssistant: John is an engineer..."
Question: "What is his job?"
Rewrite as: "What is John's job?"
History: {chat_history}
Question: {question}
Rewritten question:"""
# Define RAG answer generation prompt
rag_prompt = """You are a helpful AI assistant. Please answer the user's question based on the provided context information.
If there is no relevant information in the context, please state that you don't know and don't make up answers.
Chat history:
{chat_history}
Context information:
{context_str}
User question: {query}
Please provide a helpful and accurate answer:"""
# Create question rewriting LLM
self.contextualizer = lazyllm.OnlineChatModule(
source="deepseek",
timeout=30
).prompt(lazyllm.ChatPrompter(contextualize_prompt))
# Create main RAG pipeline
with pipeline() as ppl:
# Parallel retrieval
with parallel().sum as ppl.prl:
ppl.prl.retriever1 = Retriever(
documents,
group_name="sentences",
similarity="cosine",
topk=3
)
ppl.prl.retriever2 = Retriever(
documents,
"CoarseChunk",
"bm25_chinese",
0.003,
topk=2
)
# Reranking
ppl.reranker = Reranker(
"ModuleReranker",
model=OnlineEmbeddingModule(type="rerank", source="qwen"),
topk=3,
output_format='content',
join=True
) | bind(query=ppl.input)
# Format context
ppl.formatter = (lambda nodes, query: dict(
context_str=nodes,
query=query,
chat_history="" # Will be passed during call
)) | bind(query=ppl.input)
# LLM generates answer
ppl.llm = lazyllm.OnlineChatModule(
source="deepseek",
stream=False,
timeout=60
).prompt(lazyllm.ChatPrompter(rag_prompt, extra_keys=["context_str", "chat_history"]))
self.pipeline = ppl
print("RAG pipeline initialized")
def contextualize_question(self, question: str) -> str:
"""Reformulate question based on chat history"""
if not self.chat_history:
return question
# Build historical conversation text
history_text = ""
for msg in self.chat_history[-6:]: # Last 3 turns of conversation
if msg["role"] == "user":
history_text += f"User: {msg['content']}\n"
elif msg["role"] == "assistant":
history_text += f"Assistant: {msg['content']}\n"
try:
# Pass parameters in dictionary format
response = self.contextualizer({
"messages": [
{"role": "system",
"content": "You are an assistant that helps rewrite questions. Please rewrite the user's question based on chat history to make it standalone and understandable."},
{"role": "user",
"content": f"Based on the following chat history, rewrite the question:\n\nChat history:\n{history_text}\n\nQuestion: {question}"}
]
})
return response.strip()
except Exception as e:
print(f"Question rewriting failed: {e}")
return question
def _format_chat_history(self, messages: List[Dict], max_turns: int = 3) -> str:
"""Format chat history"""
history = []
# Take recent conversation turns
for msg in messages[-max_turns * 2:]: # Each turn includes question and answer, so multiply by 2
if msg["role"] == "user":
history.append(f"User: {msg['content']}")
elif msg["role"] == "assistant":
history.append(f"Assistant: {msg['content']}")
return "\n".join(history)
def chat(self, question: str) -> str:
"""Process single turn conversation"""
# 1. Reformulate question
contextualized_question = self.contextualize_question(question)
print(f"Contextualized question: {contextualized_question}")
# 2. Build historical conversation text
history_text = self._format_chat_history(self.chat_history, max_turns=4)
# 3. Generate answer through RAG pipeline
try:
response = self.pipeline(
contextualized_question,
chat_history=history_text
)
# 4. Update chat history
self.chat_history.append({"role": "user", "content": question})
self.chat_history.append({"role": "assistant", "content": response})
# 5. Keep history within reasonable range
if len(self.chat_history) > 20:
self.chat_history = self.chat_history[-20:]
return response
except Exception as e:
error_msg = f"Error generating answer: {e}"
print(error_msg)
return error_msg
# Global RAG system instance
rag_system = None
@fc_register("tool")
def conversational_rag_chat(question: str) -> str:
"""
Multi-turn conversational RAG tool
Args:
question (str): User question
Returns:
str: RAG system's answer
"""
global rag_system
if rag_system is None:
rag_system = ConversationalRAGPipeline()
return rag_system.chat(question)
def create_rag_agent():
"""Create RAG agent"""
# Create ReactAgent with integrated RAG tools
agent = lazyllm.ReactAgent(
llm=lazyllm.OnlineChatModule(model='Qwen3-32B', timeout=60),
tools=["conversational_rag_chat"],
max_retries=3,
return_trace=False,
stream=False
)
return agent
def start_web_interface():
"""Start web interface"""
print("Starting multi-turn conversational RAG system web interface...")
try:
# Create RAG agent
agent = create_rag_agent()
# Start web interface
web_module = lazyllm.WebModule(
agent,
port=8849,
title="Multi-turn Conversational RAG System (LazyLLM)"
)
print(f"Web interface started: http://localhost:8849")
print("Press Ctrl+C to stop service")
web_module.start().wait()
except KeyboardInterrupt:
print("\nStopping service...")
except Exception as e:
print(f"Failed to start: {e}")
if __name__ == "__main__":
# Start web interface
start_web_interface()
示例运行结果
<think>好的,用户问的是任务分解的标准方法是什么,然后在得到答案后需要查找该方法的常见扩展。首先,我需要确定任务分解的标准方法有哪些。常见的任务分解方法包括工作分解结构(WBS)、目标树、任务列表等。其中,WBS应该是项目管理中最常用的标准方法之一,它通过将项目逐层分解为更小的任务来组织工作。
接下来,用户可能需要具体的步骤或如何应用这些方法。不过根据问题,用户首先想知道标准方法是什么,所以应该先回答这个部分。然后,当用户确认答案后,再进一步查找该方法的常见扩展。例如,WBS的扩展可能包括基于生命周期的分解、按交付成果分解、或者结合敏捷方法的用户故事分解等。
现在需要检查是否有必要使用工具来获取信息。由于我的知识截止到2023年10月,关于任务分解的标准方法和其扩展可能已经足够,但为了确保准确性,可能需要调用内部的知识库或数据库来验证当前常用的扩展方法。不过根据已有的知识,我可以直接回答标准方法,然后建议下一步操作是否需要工具辅助查找扩展内容。
根据用户的指示,每次回答前必须有一个Thought,并且可能需要调用工具。但在这个情况下,标准方法我已经知道,所以可以先给出答案,然后询问是否需要进一步的信息。或者,如果用户的问题需要更详细的扩展,可能需要使用工具来搜索相关资料。但考虑到问题分为两部分,先回答第一部分,再处理第二部分可能更合适。
</think>
Thought: 用户询问任务分解的标准方法及其次要步骤的扩展。我需要先明确标准方法的具体内容,再提供扩展方向。
Answer: 任务分解的标准方法通常包括以下步骤:
1. **定义目标**:明确最终交付成果或目标;
2. **层级划分**:将任务按逻辑关系分解为子任务(如工作分解结构WBS);
3. **资源分配**:为每个子任务分配人力、时间等资源;
4. **优先级排序**:确定任务执行顺序;
5. **监控与反馈**:跟踪进度并调整计划。
若需进一步了解该方法的常见扩展(如敏捷分解、目标树分析等),可指定具体领域或应用场景,我将补充详细信息。
下一步
我们已经介绍了构建基本会话式问答应用的步骤:
- 我们使用链来构建一个可预测的应用,该应用基于聊天历史来理解问题上下文
- 我们使用智能体来构建一个可以对查询序列进行迭代的应用
要探索不同类型的检索器和检索策略,请访问 LazyLLM 的检索组件文档。
要了解更高级的智能体架构,请查看 LazyLLM 的智能体文档和示例。