🐱 LazyLLM 入门文档
0. 文档目录
- 1. 写在前面
- 2. Hello World with LazyLLM
- 3. Prompt 设计:让模型输出可控
- 4. 实现一个最小的 RAG 系统
- 5. RAG 是怎么运行的?
- 6. 使用 Pipeline 组织和管理大模型流程
- 7. 使用 Agent 处理非固定流程的任务
- 8. 基于 LazyLLM 的进阶使用方向
1. 写在前面
随着大模型能力的提升,越来越多的开发者开始尝试将其引入实际系统。但在工程实践中,真正的挑战往往不在于“能不能调用模型”,而在于如何把模型、数据和流程组织起来,使系统可用且可维护。
LazyLLM 正是围绕这一问题设计的。 它关注的是如何以更工程化的方式,将大模型能力嵌入到应用流程中。
本教程将从实际使用出发,带你逐步了解 LazyLLM 的核心用法,并最终跑通一个完整、可执行的大模型应用流程。
1.1 阅读本教程前的能力要求
本教程面向具有一定编程经验、但不一定熟悉大模型系统的读者。
在开始之前,你只需要具备以下基础:
-
能够阅读和编写基础的 Python 代码
-
熟悉基本的开发流程,如安装依赖、运行脚本
-
理解“输入 → 处理 → 输出”的基本调用逻辑
如果你此前没有接触过 RAG 或 Agent,也不影响阅读和实践。
1.2 本教程将帮助你掌握的能力
完成本教程后,你将能够使用 LazyLLM 搭建一个基础但完整的大模型应用,并对其运行方式形成清晰认识,包括:
-
启动并调用在线大模型服务
-
通过 Prompt 与输出处理机制提升结果稳定性
-
构建并运行一个最小可用的 RAG 流程
-
理解 RAG 中数据的基本流转方式
-
定义 Tool 并构建基础 Agent 示例
-
在效果或运行异常时具备基本的排查思路
1.3 本教程的内容边界与侧重点
为了保证入门阶段的学习体验,本教程聚焦于工程实践与使用直觉,不会深入讨论:
-
大模型底层算法与数学原理
-
不同模型架构之间的系统性比较
-
复杂 Agent 系统的调度与规划算法
如果你对这些内容感兴趣,可以在完成本教程后,参考后续的进阶文档。
2. Hello World with LazyLLM
在正式构建复杂流程之前,我们先从最简单的一步开始: 成功调用一次大模型,并拿到返回结果。
这一章的目标并不复杂,但非常关键。只要你能够顺利完成本章内容,就说明你的环境配置和基本使用方式都是正确的,后续章节也会更加顺利。
2.1 准备模型访问所需的 API Key
-
运行环境配置
在准备 API Key 之前,需要先完成 LazyLLM 的运行环境配置,包括依赖安装和基础设置。 这是为了确保后续示例代码可以直接运行,避免在环境问题上分散注意力。
具体配置步骤请参考官方文档。
-
API Key 设置
LazyLLM 本身并不提供模型服务,而是通过接入各类在线或本地模型来工作。 为了方便快速上手,本教程中的示例将统一使用在线模型。因此,在调用在线模型之前,你需要先准备好对应服务的 API Key。
API Key 的申请方式参考官方文档。
在本教程中,我们以
SenseNova在线模型为例,请在本地环境中配置SENSENOVA_API_KEY环境变量:
设置完成后,LazyLLM 在运行时会自动从环境变量中读取对应的 Key。
说明
不同模型服务的环境变量名称可能不同,具体以所使用的平台为准。本教程后续示例将以
SenseNova配置方式为例。
2.2 使用 LazyLLM 构造一个大模型
在 LazyLLM 中,大模型通常以 Module 的形式存在。
Module 的职责是:接收输入,调用模型,并返回结果。
下面是一个最简单的示例,用于构造一个在线大模型并发送请求:
import lazyllm
llm = lazyllm.OnlineChatModule(
source="sensenova",
model="SenseNova-V6-5-Pro"
)
response = llm("你好,简单介绍一下你自己。")
print(response)
在这个示例中:
-
OnlineChatModule用来构造一个在线聊天大模型的实例 -
source指定模型服务来源 -
model指定具体的模型名称
你可以将这个 llm 理解为一个普通的 Python 可调用对象: 向它传入输入,它会返回模型的输出。
2.3 运行一次最简单的对话
当代码成功运行后,你应该可以在终端中看到模型返回的文本结果。 该示例的运行结果如下:

这一过程虽然简单,但已经包含了 LazyLLM 的几个核心特点:
-
模型以模块(Module)的形式被统一封装
-
模块通过调用的方式参与到程序流程中
-
输入和输出都以明确的数据形式存在
后续无论是 Prompt、RAG 还是 Agent,本质上都是在组合和组织这些模块。
2.4 常见问题与排查思路
在第一次运行示例时,如果没有成功得到返回结果,通常可以从以下几个方面进行排查。
2.4.1 API Key 未正确配置
如果模型服务返回认证相关错误,首先检查:
-
API Key 是否已正确设置为环境变量
-
当前运行环境是否能够读取到该环境变量
可以在 Python 中简单打印环境变量进行确认:
import os
print(os.environ["LAZYLLM_SENSENOVA_API_KEY"])
print(os.environ["LAZYLLM_SENSENOVA_SECRET_KEY"])
2.4.2 模型名称或来源配置错误
如果出现模型不存在或无法访问的错误,通常是由于:
-
source 参数填写不正确
-
model 名称与实际服务不匹配
建议先参考对应模型服务的官方文档,确认可用的模型名称。
2.4.3 网络或服务不可用
如果请求长时间无响应或直接失败,也可能是网络或服务状态问题。此时可以尝试:
-
检查网络连接
-
稍后重试
-
更换其他可用的模型服务
3. Prompt 设计:让模型输出可控
在前一章中,我们已经成功调用了大模型,并拿到了返回结果。 但在真实应用中,“能返回结果”远远不够,更重要的是返回结果是否符合预期,以及是否能够被后续程序稳定地处理。
Prompt 正是解决这一问题的核心工具。
3.1 理解 Prompt 在大模型系统中的作用
从使用角度来看,Prompt 可以理解为你向大模型说明任务的方式。 它不仅包含用户的问题,也包含对输出形式、风格以及约束条件的描述。
在一个大模型系统中,Prompt 的作用主要体现在两个方面:
-
指定模型“要做什么”
-
影响模型“如何给出结果”
换句话说,Prompt 并不只是自然语言输入,而是模型执行任务时的重要上下文。
3.2 理解大模型输出的非确定性特征
在实际使用中,你很快会发现一个问题: 即使输入完全相同,大模型的输出也可能存在差异。
这是大模型的固有特性,并不意味着模型或框架存在问题。 但对于工程系统来说,这种不稳定性往往会带来麻烦。
一个工程中常见的输出失控示例
假设我们希望模型返回一段结构化数据,供程序后续解析使用。
例如,我们希望模型返回如下格式的结果:
如果 Prompt 设计不当,模型可能会返回类似下面的内容:
3.3 使用工程化手段约束模型输出结构
在前面的内容中,我们已经看到,仅依赖 Prompt 往往无法保证模型输出在工程上的可用性。 当模型的输出需要被后续程序解析、存储或进一步处理时,就需要引入工程化手段来约束输出结构。
需要说明的是,LazyLLM 中并不只有一种方式可以处理模型输出。
本节将以 Formatter 和 Extractor 为例,分别介绍两种常见思路:
-
约束模型的生成方式,尽量让模型“按要求输出”
-
将任务建模为结构化抽取,直接返回可用结果
下面我们仍然使用同一个简单示例,对比不同方式下的效果。
3.3.1 示例任务说明
从一段自然语言中抽取用户的姓名和年龄,并以 JSON 形式返回。
输入文本为:
期望的输出结构为:
3.3.2 不使用任何工具时的输出情况
首先来看只使用 Prompt 的情况。
import lazyllm
llm = lazyllm.OnlineChatModule(
source="sensenova",
model="SenseNova-V6-5-Pro",
)
PROMPT = """
你是一个信息抽取器。
请从【输入文本】中抽取用户的姓名和年龄,并严格只输出 JSON,不要输出任何解释、说明或多余内容。
【输出格式】:
{{
"name": "示例名字",
"age": 0
}}
【输入文本】:
"""
llm_raw = llm.prompt(PROMPT)
result = llm_raw("大家好,我叫张三,今年 28 岁,在上海工作。")
print(result)
在这种情况下,模型可能返回符合预期的 JSON, 也可能在输出中夹带解释性文字,或者在格式上产生细微偏差。
如下图所示,在模型的输出中夹带了思考的过程,虽然最后产生了符合格式要求的 json 结果,但这种不确定性在工程系统中往往是不可接受的。

3.3.3 使用 Formatter 规整模型输出格式
第一种工程化思路是: 尽量约束模型的输出形态,让结果更接近目标格式。
LazyLLM 中可以通过 Formatter 实现这一点。
from lazyllm.components.formatter import JsonFormatter
llm_fmt = llm.prompt(PROMPT).formatter(JsonFormatter())
fmt_result = llm_fmt("大家好,我叫张三,今年 28 岁,在上海工作。")
print(fmt_result)
使用 Formatter 后,模型的输出通常会更加“干净”, 例如减少自然语言说明,输出更接近标准 JSON 字符串。

需要注意的是:
-
Formatter 主要作用于输出格式
-
是否完全符合 schema,仍然依赖模型的配合程度
3.3.4 使用 Extractor 进行结构化抽取
另一种思路是: 不要求模型“自己输出标准结果”,而是把任务建模为抽取问题。
在 LazyLLM 中,可以通过 Extractor 来完成这种模式。
import json
from lazyllm.tools.tools import JsonExtractor
extractor = JsonExtractor(
base_model=llm,
schema='{"name": "", "age": 0}',
field_descriptions={'name': '姓名', 'age': '年龄'}
)
ext_result = extractor("张三的年龄是20岁,李四的年龄是25岁")
print(ext_result)
使用 Extractor 的输出结果如下:

在这种方式下:
Extractor 会调用底层模型完成推理
-
按照指定的 schema 返回结构化结果
-
返回值可以直接作为 Python 对象使用
-
这种方式更适合字段明确、结构固定的抽取类任务
3.4 常见问题与排查思路
在使用 Formatter 或 Extractor 时,常见的问题多半与任务设置方式有关。 下面通过几个典型情况,给出更清晰的处理思路。
3.4.1 返回结果缺少字段,或字段值为空
在使用 Extractor 时,可能会发现返回结果中缺少某些字段,或字段存在但值为空。 这通常是因为 schema 设计过于复杂,模型难以一次性稳定抽取所有信息。可以按照如下步骤排查:
-
简化 schema,只保留最核心的字段
-
优先选择文本中最容易直接判断的信息
-
确认核心字段稳定后,再逐步增加其他字段
3.4.2 字段类型与预期不一致
常见表现包括数字被返回为字符串,或列表被返回为单个值。 这通常说明模型仍然在“生成文本”,而不是严格执行抽取任务。解决思路如下:
-
明确当前任务是否需要类型稳定的数据结构
-
如果需要,优先使用 Extractor
-
不要通过不断修改 Prompt 来强行修正类型问题
3.4.3 输入内容过多,导致抽取失败或结果混乱
当输入文本较长、信息较杂,或 Prompt 中包含多个目标时,抽取结果可能变得不稳定。 模型很难在一次任务中同时完成理解和抽取。这种情况下需要:
-
避免一次任务承担过多目标
-
先缩小需要处理的文本范围
-
再对精简后的内容进行结构化抽取
4. 实现一个最小的 RAG 系统
在前一章中,我们讨论了如何让模型输出变得更可控。
这一章将引入一个新的问题:当模型本身不知道答案时,该怎么办?
这正是 RAG(Retrieval-Augmented Generation) 要解决的问题。
4.1 为什么需要 RAG
大模型的能力来源于训练数据,但它并不具备“实时访问外部知识”的能力。 这意味着,模型更擅长“基于已有知识进行推理和表达”,而不擅长“按需查资料”。
在实际应用中,这一限制会逐渐显现出来。例如:
-
问题涉及私有文档或内部知识
-
问题超出了模型的训练范围
-
需要基于指定材料进行回答,而不是“自由发挥”
在这些场景下,即使模型本身能力很强,也往往无法给出可靠结果。 问题并不在于模型“不会回答”,而在于它拿不到需要参考的信息。
一种自然的解决思路是:
在让模型回答之前,先把相关信息找出来,再一并提供给模型。
RAG(Retrieval-Augmented Generation)正是基于这一思路提出的。 它并不试图让模型“记住更多知识”,而是通过引入检索过程,让模型在生成答案时能够参考外部内容。
从流程上看,RAG 可以简化理解为三个连续的步骤:
-
将问题转化为可检索的表示
-
从知识库中检索相关内容
-
将检索结果作为上下文交给模型生成答案
通过这种方式,模型的生成过程不再完全依赖自身知识,而是建立在可控、可更新的外部信息基础之上。
4.2 使用 LazyLLM 构建一个最小 RAG 流程
在 LazyLLM 中,RAG 通常通过 pipeline 的方式来组织。 pipeline 并不是某种“特殊算法”,而是一个顺序执行的处理流程。下面我们先构建一个最小可运行的 RAG 示例。
4.2.1 示例准备:文档与模型
假设我们有一个简单的本地文档目录,里面存放了一些文本文件,用作知识库。
import lazyllm
# 加载文档
documents = lazyllm.Document(
dataset_path="./docs"
)
# 构造模型
prompt = "下面是一个问题,运用所学知识来正确回答提问."
llm = lazyllm.OnlineChatModule(
source="sensenova",
model="SenseNova-V6-5-Pro",
)
# 设置模型 prompt
llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
在这个示例中:
-
Document负责加载和管理原始文档 -
模型仍然作为一个独立的模块存在
说明:
关于
extra_keys字段的使用方法,详情参考详细的接口文档。
4.2.2 构建检索模块
接下来,我们需要一个检索模块实例,用于从文档中找到与问题相关的内容。
retriever = lazyllm.Retriever(
doc=documents,
group_name="CoarseChunk",
similarity="bm25_chinese",
topk=3
)
这个 retriever 就是后续流程中的检索模块。它通过一组参数完成初始化,并封装了完整的“输入问题 → 返回相关内容”的逻辑。
在使用时,你只需要传入用户问题作为输入,它就会返回一组与之最相关的文本片段作为输出,具体的输入输出格式会在 5.2.2章节 介绍。
关于 retriever 参数的详细介绍,如果有兴趣可以参考文档。
4.2.3 使用 pipeline 串联 RAG 流程
有了模型和检索模块之后,就可以通过 pipeline 将它们串联起来。
from lazyllm import bind
with lazyllm.pipeline() as rag_ppl:
rag_ppl.retriever = retriever
rag_ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | bind(query=rag_ppl.input)
rag_ppl.llm = llm
此时,一个最小的 RAG 流程已经搭建完成:
-
问题先进入 retriever
-
formatter 调整中间数据,转换为 llm 可以处理的格式
-
format 之后的数据交给 llm 进行生成
pipeline 会按照添加顺序依次执行模块。
4.2.4 运行一次完整的 RAG 示例
当代码成功运行时,模型的回答将基于检索到的文档内容,而不是凭空生成:
夜来香是萝藦科夜来香属的植物,又称“夜香花”“夜兰香”,主要特征如下:
1. **形态特征**
为多年生缠绕藤本植物,小枝柔弱有毛,叶片宽卵形或心形,对生;花冠黄绿色,夜间散发浓郁清香味,故得名“夜来香”。其花序为伞房状聚伞花序,花朵可达30朵,花期多在夏秋傍晚开放。
2. **分布与用途**
原产于中国华南地区,现广泛栽培供观赏,常用于庭院、窗前绿化。其花和嫩芽可作半野生蔬菜食用,中医认为其具有清肝明目的功效,可治疗目赤肿痛、麻疹上眼等症。
3. **注意事项**
夜间释放的香气含丁香生物碱等成分,可能引发头晕、失眠或过敏反应,敏感人群需注意避免长时间接触。此外,其乳汁和部分组织有毒性,需谨慎处理。
总结:夜来香是一种兼具观赏、食用及药用价值的植物,但需注意其潜在毒性及气味对健康的影响。
4.3 常见问题与排查思路
在第一次搭建 RAG 流程时,常见问题通常出现在流程连接和数据准备阶段。
4.3.1 检索结果为空或数量过少
这种情况通常与以下因素有关:
-
文档未被正确加载( Document 的 dataset_path 参数要指定到文件夹,而不是文件 )
-
文档内容过少或过于零散
-
检索参数设置过于严格
建议优先确认文档是否被成功读取,其次再调整检索参数。
4.3.2 检索结果与问题不相关
如果检索到的内容明显无关,可能是因为:
-
文档切分方式不合理
-
检索方式不适合当前文本类型
-
返回结果数量(
topk)设置过小
在排查时,可以先单独运行 Retriever,观察其返回的文本内容。
4.3.3 模型回答未体现检索内容
当模型输出看起来“像是凭空回答”时,往往不是模型的问题,而是流程问题:
-
检索结果未正确传入模型
-
Prompt 未明确要求模型基于给定内容回答
此时应优先检查模块之间的数据是否真的被串联起来。
5. RAG 是怎么运行的?
在前一章中,我们已经跑通了一个最小的 RAG 系统。 但在实际使用中,你很快会关心:检索到的内容是如何参与生成的,以及当效果不理想时,问题可能出现在流程的哪一步。要回答这些问题,需要进一步拆开来看一次 RAG 请求在系统中的运行过程。
5.1 从整体上理解 RAG 的执行流程
从 LazyLLM 的角度来看,一个 RAG 系统并不是“一个黑盒模块”,而是由多个模块顺序协作完成的流程。
在最典型的 RAG 场景中,整体流程可以概括为:
-
接收用户问题
-
使用检索模块查找相关文档
-
将检索结果作为上下文传入模型
-
由模型基于上下文生成答案
LazyLLM 通过 pipeline 将这些步骤串联起来,使得每一步的输入和输出都是明确的。
5.2 RAG 中的模块协作与数据流动
下面通过一个完整示例,直观地了解一次 RAG 请求是如何被处理的。
5.2.1 Retriever:检索
Retriever 是 RAG 的核心组件之一,用来根据问题查找相关内容。
它的输入通常是用户问题(或其向量表示),输出是一组与问题相关的文本片段。示例:
query = "什么是夜来香?"
print(f"========== 输入 ==========\n{query}")
retrieved_docs = retriever(query)
for doc in retrieved_docs:
print(f"========== 输出 ==========\n{doc.text}")
输出结果:
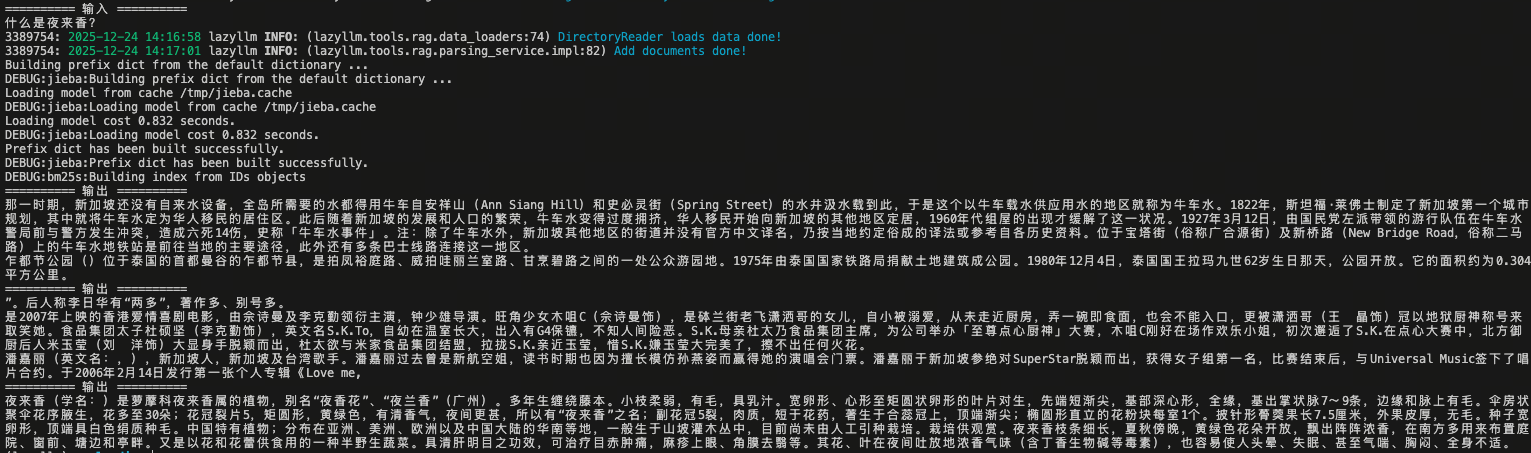
5.2.2 Reranker:重排(可选)
Reranker 接收用户问题和一组候选文本(retriever 检索出来的文本),对这些文本与问题的相关性进行重新评估。 它不会生成新内容,而是对已有文本进行重新排序。
reranker = Reranker('ModuleReranker', model='bge-reranker-large', topk=2)
reranked_docs = reranker(retrieved_docs)
for doc in reranked_docs:
print(f"========== 重排后的文档 ==========\n{doc.text}")
print(f"---------- 相关性分数 ----------\n{doc.relevance_score}")
重排结果如下,可以看到和用户输入相关性更高的文档排序更靠前,分数也更高。

需要注意的是,Reranker 并不是 RAG 的必选组件,而是用于提升效果的可选步骤。如果不使用 Reranker,可以直接把 retrieved_docs 作为输入传递给 LLM。
5.2.3 LLM:大模型生成答案
基于前面模块生成的结果,LLM 的输入通常是一段拼接好的文本:原始 prompt + 检索到的 context。 模型会基于这段输入生成最终回答:
rerank_contexts = [doc.text for doc in reranked_docs]
context_str = "\n-------------------\n".join(rerank_contexts)
res = llm({"query": query, "context_str": context_str})
print(f'---------- llm result ----------')
print(res)

6. 使用 Pipeline 组织和管理大模型流程
读到这里,你可能已经发现,一旦把检索、格式化、模型调用这些步骤串在一起,代码很快就会变得不太好看。 问题往往不在于“某一步怎么写”,而在于,当步骤越来越多时,怎么把它们组织清楚、也方便以后改动。 在 LazyLLM 中,这个问题是通过 pipeline 来解决的。
6.1 Pipeline 的核心思想
Pipeline 的核心思想很简单:
把一连串有依赖关系的步骤,按照固定顺序串成一条清晰的执行流程。
在 LazyLLM 中,每一步只关心三件事:
- 接收什么输入
- 产出什么输出
- 把结果交给下一步
这样做的目的不是“写法更高级”,而是让流程本身一眼就能看懂、也方便后续调整。
6.2 用 Pipeline 表达 RAG 的执行顺序
在 RAG 这样的流程中,真正重要的不是某一个模块,而是这些模块按什么顺序被执行。 使用 pipeline 后,这个顺序可以被直接写在代码里:
with lazyllm.pipeline() as rag_ppl:
rag_ppl.retriever = retriever
rag_ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | bind(query=rag_ppl.input)
rag_ppl.llm = llm
从上到下阅读这段代码,可以清楚看到整个流程的走向:
- 用户输入先进入检索模块
- 检索结果被整理成模型需要的输入
- 最终由模型生成答案
pipeline 做的事情只有一件:把执行顺序写清楚。 流程本身没有发生变化,但代码变得更直观,也更容易维护。
6.3 Pipeline 带来的工程价值
在实际使用中,pipeline 的价值并不体现在某一个具体功能上,而体现在流程本身变得更好理解、更好维护。
-
pipeline 让流程结构变得明确且稳定。 每个步骤在流程中的位置是固定的,执行顺序是清晰的,这使得复杂流程不再依赖隐含的代码逻辑,而是以结构化的方式被定义下来。
-
pipeline 显著降低了调试成本。 当系统输出不符合预期时,可以沿着 pipeline 的顺序逐步检查每个模块的输出,而不是在一整段代码中反复定位问题来源。
-
pipeline 也让流程的调整和扩展更加可控。 无论是插入新模块、替换已有模块,还是调整流程顺序,都可以在不破坏整体结构的前提下完成。
从工程角度看,pipeline 做的事情可以总结为: 把原本隐含在代码里的流程结构,明确地写出来。 一旦流程本身变得清楚,后续的开发、调试和修改都会轻松很多。
如果你希望进一步了解 pipeline 的实现原理,或者在更复杂场景中使用 pipeline,可以参考 LazyLLM 的进阶文档。
7. 使用 Agent 处理非固定流程的任务
在前面的章节中,我们已经通过 pipeline 组织了清晰、稳定的处理流程,例如 RAG。 但在实际应用中,并不是所有任务都适合被提前设计成固定流程。
当系统需要根据中间结果动态决定下一步行为时,就需要引入 Agent。
7.1 理解 Agent 在非固定流程中的作用
在前面的章节中,我们已经用 pipeline 把流程组织了起来,比如 RAG。这类场景的特点是:每一步做什么、按什么顺序执行,在写代码时就能提前确定。
但在实际应用中,并不是所有流程都这么清晰。有些时候,下一步该不该做、要不要再试一次,甚至要调用哪种能力,都取决于当前结果。这类判断很难一开始就写死。 如果仍然用固定流程去覆盖这些情况,代码很快就会变得复杂且难以维护。这并不是 pipeline 的问题,而是流程本身并不固定。
Agent 用来解决的正是这种场景。它不要求你提前规定完整流程,而是由模型在运行过程中,根据当前输入和中间结果决定下一步该做什么。
简单来说:
当流程可以提前确定时,使用 pipeline;
当流程需要在运行过程中被决定时,引入 Agent。
7.2 理解 Tool 在 Agent 决策中的角色
在 Agent 系统中,Tool 不是固定流程中的一步,而是模型在运行过程中可以选择使用的能力。
开发者不再指定“什么时候调用哪个函数”, 而是提供一组工具,让模型根据当前任务自行决定是否调用、调用哪一个。
因此,Tool 的本质是 Agent 的可选行动集合。
7.3 定义一个可被 Agent 调用的 Tool
定义 Tool 时,应尽量保持能力单一、边界清晰。 复杂逻辑不利于模型理解和正确调用。
最小可用的 Tool 示例如下,在该例子中,我们定义了一个加法函数和一个乘法函数,并利用 @fc_register 装饰器把它注册为 lazy 的一个工具,这样 Agent 就可以直接根据函数名调用这个工具:
from lazyllm.tools import fc_register
@fc_register("tool")
def multiply_tool(a: int, b: int) -> int:
"""
Docstring for multiply_tool
:param a: Description
:type a: int
:param b: Description
:type b: int
:return: Description
:rtype: int
"""
return a * b
@fc_register("tool")
def add_tool(a: int, b: int):
"""
Docstring for add_tool
:param a: Description
:type a: int
:param b: Description
:type b: int
"""
return a + b
7.4 使用 Agent 调用自定义 Tool
将 Tool 提供给 Agent 后,模型会在运行时判断是否需要使用它。
在这个过程中,执行路径由模型决定,而不是由代码写死。
Agent 在分析问题 “20+(2*4)”时,会主动调用 multiply_tool 和 add_tool 工具进行计算。
from lazyllm.tools import ReactAgent
tools = ["multiply_tool", "add_tool"]
llm = lazyllm.OnlineChatModule(source="sensenova", model="DeepSeek-V3")
agent = ReactAgent(llm, tools)
query = "What is 20+(2*4)? Calculate step by step."
res = agent(query)
print(res)
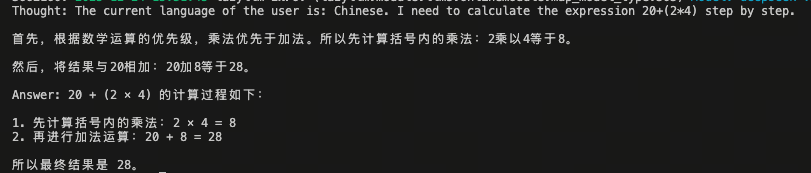
7.5 Agent 的适用场景与使用边界
Agent 更适合处理以下问题:
-
流程无法提前完全确定
-
需要根据中间结果决定下一步
-
需要组合多种能力完成任务
如果流程是确定的,pipeline 通常更简单、也更稳定。 Agent 的自由度越高,对约束和设计的要求也越高。
如果想要了解更多 AI Agent 相关的细节,可以参考 Agent 进阶文档。
8. 基于 LazyLLM 的进阶使用方向
读到这里,你已经完成了 LazyLLM 的核心入门路径: 能够调用模型、组织流程、构建 RAG 系统,并理解 Agent 的使用场景。 在实际项目中,不同需求会沿着不同方向继续深入。 下面列出一些常见且实用的进阶方向,你可以根据自己的场景选择性探索。
-
深入 Prompt 设计与输出控制 当系统开始对接下游程序或业务逻辑时,如何让模型输出更加稳定、可控,会变得尤为重要。 👉 参考文档
-
优化 RAG 的检索与召回效果 在多数 RAG 场景中,效果瓶颈往往不在模型,而在检索和重排阶段。 包括文档切分方式、检索策略以及参数选择等问题。 👉 参考文档
-
微调实践:让模型更贴合你的领域 当通用模型在特定领域表现不稳定时,可以通过微调,让大模型或向量模型更好地理解你的业务语境和数据分布。 👉 参考文档
-
加速执行:用缓存、异步与高效引擎提升性能 在请求量大、响应时效要求高的场景中,可通过缓存中间结果、异步执行流程以及接入高性能向量引擎,显著提升系统响应速度与资源利用率。 👉 参考文档
-
多模态 RAG:处理图文音视频等复杂内容 当应用涉及图片、PDF、语音或视频等非文本信息时,可以构建多模态 RAG 系统,支持跨模态检索与问答,拓展大模型的应用边界。 👉 参考文档
-
Agentic RAG:构建具备决策能力的问答系统 当单轮问答无法满足需求,或问题需要多步思考与信息整合时,可以结合 Agent 机制,让系统具备调用工具、反复检索与自主决策的能力。 👉 参考文档